# 《RPC手撸专栏》第81章:结果缓存通用模型设计
作者:冰河
星球:http://m6z.cn/6aeFbs (opens new window)
博客1:https://binghe001.github.io (opens new window)
博客2:https://binghe.site (opens new window)
文章汇总:https://binghe.site/md/all/all.html (opens new window)
沉淀,成长,突破,帮助他人,成就自我。
大家好,我是冰河~~
目前,我们自己手写的RPC框架已经完成了整体设计、服务提供者的实现、服务消费者的实现、注册中心的实现、负载均衡的实现、SPI扩展序列化机制、SPI扩展动态代理机制、SPI扩展反射机制、SPI扩展负载均衡策略、SPI扩展增强型负载均衡策略、SPI扩展实现注册中心、心跳机制、增强型心跳机制、重试机制、整合Spring、整合SpringBoot、整合Docker和整合SpringCloud Alibaba等篇章,共计80+篇文章。
# 一、前言
如果一个RPC框架每次发起调用时,都完整走一遍RPC的调用流程,是很耗费时间的!
RPC框架作为分布式系统底层通信的基础设施框架,其性能的高低直接影响着整体系统的性能水平,如果每次发起RPC调用时,都完整走一遍RPC的调用流程,会极大的影响RPC框架的性能,进而影响整个分布式系统的性能。
# 二、目标
目标很明确:实现结果缓存的通用模型设计!
RPC框架除了在通信协议和编解码上进行优化来增强框架的性能外,也要能够支持在服务提供者和服务消费者端基于缓存的形式来提升框架的性能。
为了更好的在服务提供者端和服务消费者端实现缓存机制,本节的目标是:实现结果缓存的通用模型设计。
# 三、设计
如果让你设计结果缓存的通用模型的流程,你会怎么设计呢?
结果缓存的通用模型的流程如图81-1所示。
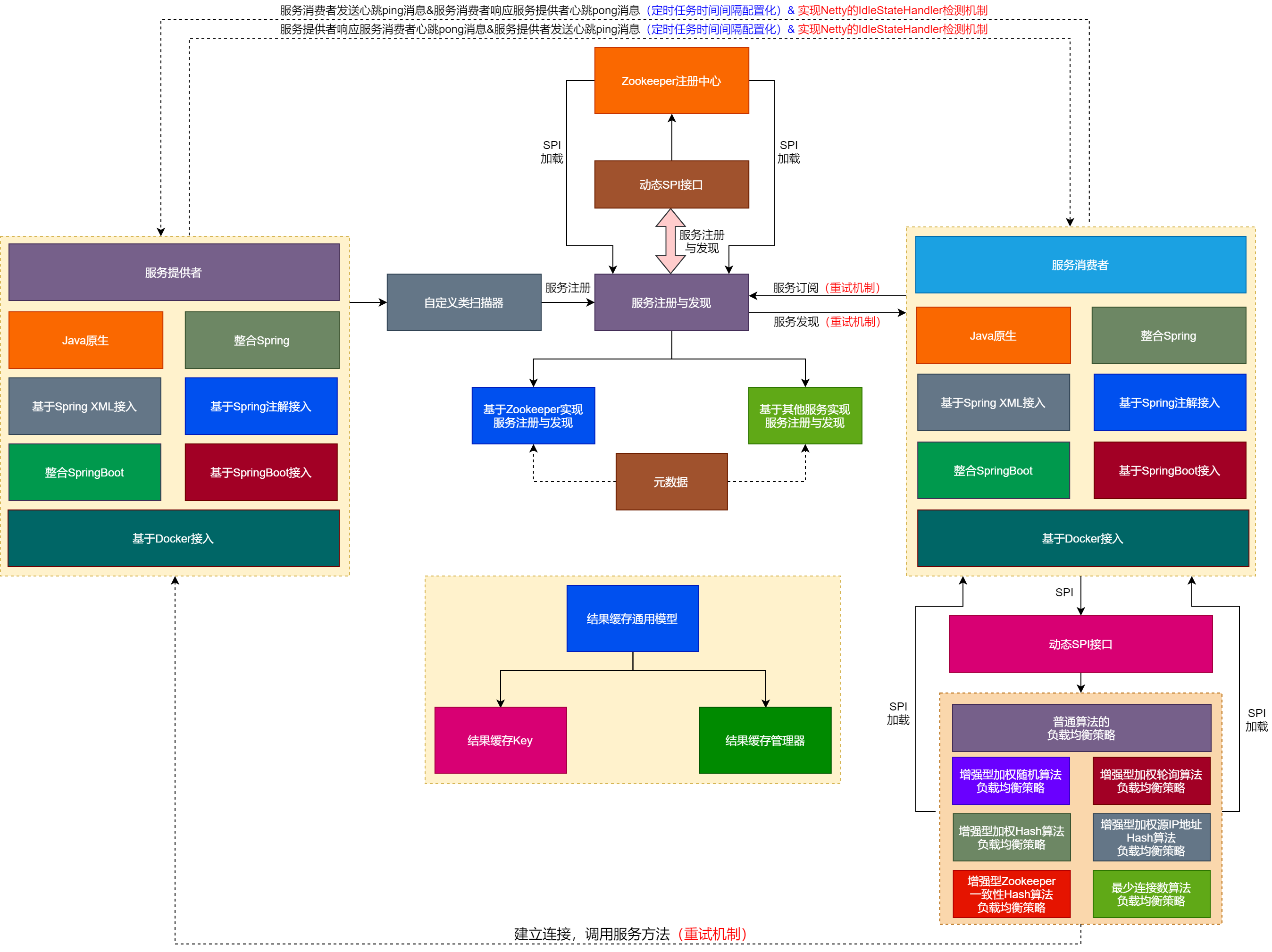
由图81-1可以看出如下信息:
(1)服务提供者会通过自定义类扫描器整合注册中心,将服务注册到注册中心。
(2)服务注册到注册中心的元数据,例如服务的名称、服务的版本号、服务地址、服务端口和服务分组等信息,元数据会贯穿整个服务的注册与发现流程。
(3)服务注册与发现SPI接口对外提供服务注册与发现的方法,服务提供者通过自定义扫描器会调用服务注册与发现SPI接口的方法实现服务注册功能。
(4)基于服务注册与发现的SPI接口,服务提供者会基于SPI接口实现多个服务注册与发现的实现类,每个实现类对应着一种注册中心服务。
(5)服务消费者会通过服务注册与发现的SPI接口订阅注册中心的服务,会从注册中心获取到服务提供者发布的服务信息,实现服务发现的功能。
(6)服务消费者从注册中心获取到服务提供者发布的服务信息后,会基于SPI机制动态加载普通算法(我们将第42章~第50章实现的负载均衡算法统称为普通算法)、基于增强型加权随机算法、基于增强型加权轮询算法、基于增强型加权Hash算法、基于增强型加权源IP地址Hash算法、基于增强型Zookeeper一致性Hash算法和最少连接数算法的负载均衡策略,从多个服务中选择一个进行远程网络连接。
(7)服务消费者会直接与根据基于SPI机制动态加载的负载均衡策略选择出的服务提供者建立连接,实现数据交互。也就是说,后续服务消费者会与服务提供者直接实现数据交互。
(8)服务消费者向服务提供者发送心跳ping消息,服务提供者响应服务消费者pong消息。服务提供者向服务消费者发送心跳ping消息,服务消费者向服务提供者响应pong消息。
(9)服务消费者发送心跳和服务提供者发送心跳,定时任务的时间间隔都是配置化的。
(10)服务提供者与服务消费者除了手动实现定时任务来实现心跳检测外,还基于Netty的IdleStateHandler实现了心跳检测机制。
(11)服务消费者支持服务订阅的重试机制、服务消费者连接服务提供者支持重试机制。
(12)服务提供者支持以Java原生程序方式和整合Spring的方式提供服务,并且实现了基于Spring XML和Spring注解的方式接入RPC框架的服务提供者。
(13)服务消费者支持以Java原生程序方式和整合Spring的方式提供服务。并且实现了基于Spring XML和Spring注解的方式接入RPC框架的服务消费者。
(14)服务提供者支持整合SpringBoot的功能,并支持基于SpringBoot接入服务提供者。
(15)服务消费者支持整合SpringBoot的功能,并支持基于SpringBoot接入服务消费者。
(16)RPC框架支持基于Docker接入服务提供者和服务消费者。
(17)结果缓存通用模型中包含:结果缓存的Key和结果缓存管理器。
# 四、实现
说了这么多,具体要怎么实现呢?
# 核心类实现关系
结果缓存通用模型设计的核心类关系如图81-2所示。
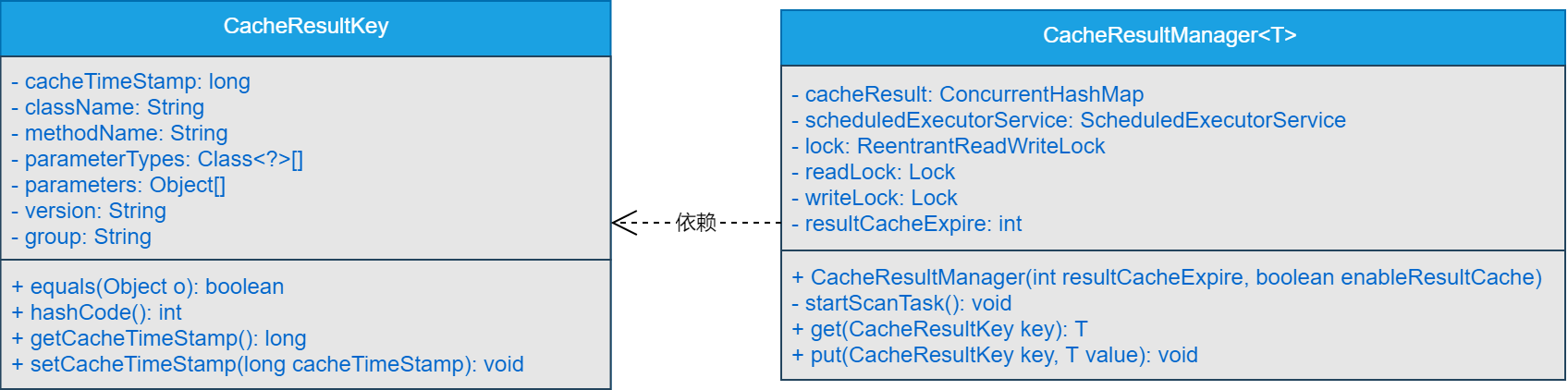
由图81-2可以看出,在结果缓存的通用模型设计中,重点提供了CacheResultKey和CacheResultManager两个类,两个类的说明如下所示。
(1)CacheResultKey类
CacheResultKey类表示缓存的Key,类中会重写hashCode方法和equals()方法,主要的依据就是className、methodName、parameterTypes、parameters、version和group相同,则创建的CacheResultKey类的对象相同。也就是说,对于发起的多个RPC调用来说,如果调用的目标类的类名、方法名、参数类型列表、参数列表相同,并且版本号和分组相同,则可以判定是调用的同一个远程方法,并且传递的参数相同,只要远程方法的结果未发生变化,则认为返回的结果是一致的,为了提高RPC框架的性能,可以将结果缓存一段时间。
(2)CacheResultManager类
CacheResultManager类为泛型类,泛型表示缓存的Value类型,而缓存的Key则是CacheResultKey类的对象。整体设计上就是在CacheResultManager类的构造方法中传入一个resultCacheExpire参数,表示缓存结果数据时长,同时会传入一个enableResultCache参数,表示是否开启结果缓存,true为开启,false为不开启。当enableResultCache参数为true,开启缓存时,会在CacheResultManager类的构造方法中,调用startScanTask()方法来扫描缓存中的数据,如果检测到缓存中的某些数据的缓存时长大于resultCacheExpire,则将这些缓存数据清除。
如果服务提供者端设置的enableResultCache参数为true,则接收到服务消费者端发送过来的数据后,首先检测结果缓存中是否存在对应的结果数据,如果存在,则直接返回结果数据。如果结果缓存中不存在对应的结果数据,则首先调用真实方法,获取结果数据后,放入缓存并返回结果数据。
如果服务消费者端设置的enableResultCache参数为true,则每次发起请求时,首先检测结果缓存中是否存在对应的结果数据,如果存在,则不再发起RPC请求,直接从缓存中获取结果数据并返回。如果结果缓存中不存在对应的结果数据,则发起RPC请求获取结果数据,并将获取到的结果数据存入缓存中,并返回结果数据。
# 查看完整文章
加入冰河技术 (opens new window)知识星球,解锁完整技术文章与完整代码
