# 《RPC手撸专栏》第43章:基于SPI扩展加权随机算法负载均衡策略
作者:冰河
星球:http://m6z.cn/6aeFbs (opens new window)
博客:https://binghe.site (opens new window)
文章汇总:https://binghe.site/md/all/all.html (opens new window)
沉淀,成长,突破,帮助他人,成就自我。
大家好,我是冰河~~
在前面的章节中,我们基于SPI扩展了JDK、Json、Hessian2、FST、Kryo和Protostuff序列化与反序列化机制,在服务消费者端基于SPI扩展了JDK、CGLib、Javassist、ByteBuddy和ASM动态代理机制。在服务提供者端,基于SPI扩展了JDK、CGLib、Javassist、ByteBuddy和ASM反射机制调用真实方法的功能。
# 一、前言
基于SPI扩展实现了随机算法负载均衡策略,我还想扩展其他的负载均衡策略!
就RPC框架在实际的使用场景而言,大部分场景下可能都是多个服务消费者对应者多个服务提供者。也就是说,无论是服务提供者,还是服务消费者,都是以集群的模式进行部署的。服务消费者会从注册中心获取到多个服务提供者的列表。此时,服务消费者就需要根据某种负载均衡的策略从多个服务提供者列表中选择一个,与其建立长连接进行数据交互。
# 二、目标
目标很明确:基于SPI扩展加权随机算法负载均衡策略!
在前面的文章中,我们基于SPI扩展了随机算法负载均衡策略,服务消费者会从多个服务提供者中随机选择一个进行网络通信。这在一定程度上能够满足我们的需求。
但是随机算法有个弊端,服务消费者每次连接服务提供者时,都是从多个服务提供者中随机选择一个进行连接。也就是说,每个服务提供者被选中的概率都是相同的。这也就意味着不管服务提供者所在的服务器的负载如何,被选中的概率基本都是相同的。如果被选中的服务提供者所在的服务器的负载很高,服务提供者的响应速度可能就会低些。如果被选中的服务提供者所在的服务器的负载很低,服务提供者的响应速度可能就会低些。
为了缩小这种服务提供者所在的服务器的性能或者负载对服务提供者响应能力的影响,我们可以基于加权随机算法对随机算法进行优化。
本章,我们就基于SPI扩展加权随机算法负载均衡策略。
# 三、设计
如果让你设计基于SPI扩展加权随机算法负载均衡策略,你会怎么设计呢?
基于SPI扩展加权随机算法负载均衡策略的流程如图43-1所示。
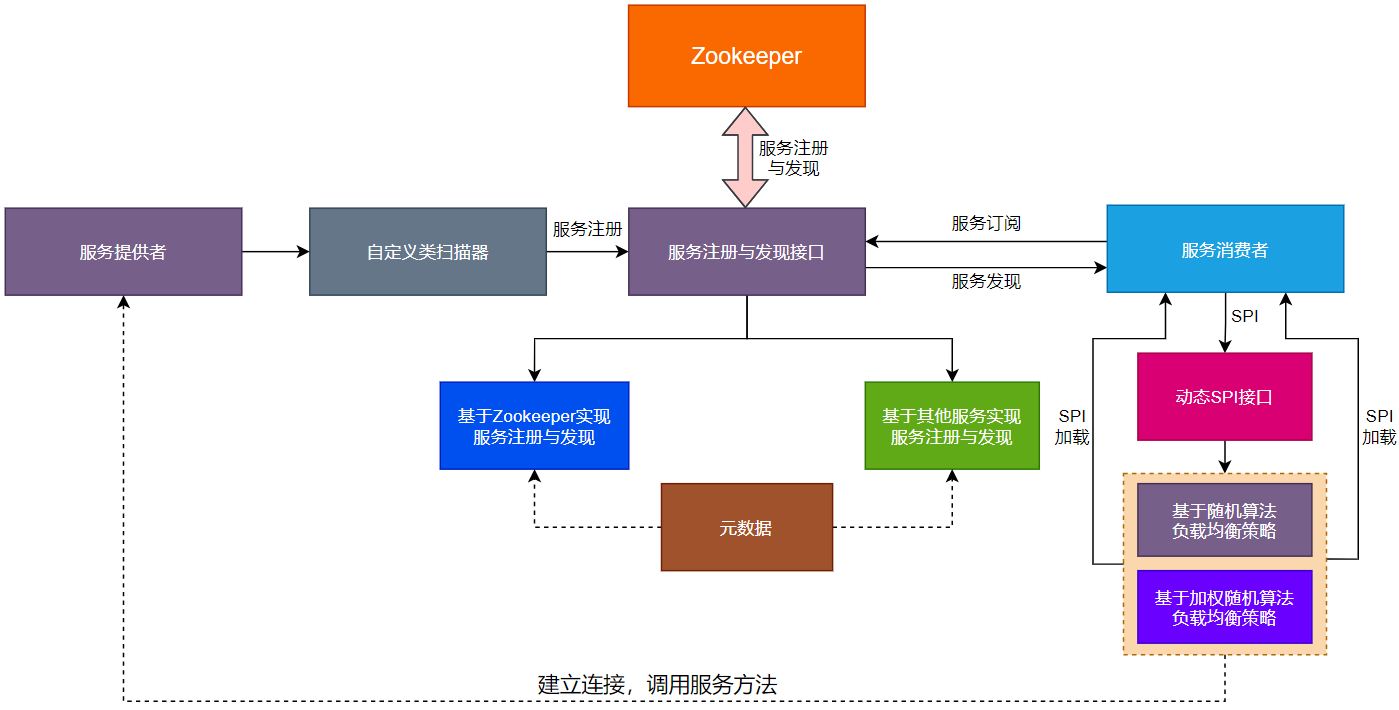
由图43-1可以看出如下信息:
(1)服务提供者会通过自定义类扫描器整合注册中心,将服务注册到注册中心。
(2)服务注册到注册中心的元数据,例如服务的名称、服务的版本号、服务地址、服务端口和服务分组等信息,元数据会贯穿整个服务的注册与发现流程。
(3)服务注册与发现接口对外提供服务注册与发现的方法,服务提供者通过自定义扫描器会调用服务注册与发现接口的方法实现服务注册功能。
(4)基于服务注册与发现的接口,服务提供者会实现多个服务注册与发现的实现类,每个实现类对应着一种注册中心服务。
(5)服务消费者会通过服务注册与发现接口订阅注册中心的服务,会从注册中心获取到服务提供者发布的服务信息,实现服务发现的功能。
(7)服务消费者从注册中心获取到服务提供者发布的服务信息后,会基于SPI机制动态加载随机算法和加权随机算法的负载均衡策略从多个服务中选择一个进行远程网络连接。
(8)服务消费者会直接与根据基于SPI机制动态加载的负载均衡策略选择出的服务提供者建立连接,实现数据交互。也就是说,后续服务消费者会与服务提供者直接实现数据交互。
# 四、实现
说了这么多,具体要怎么实现呢?
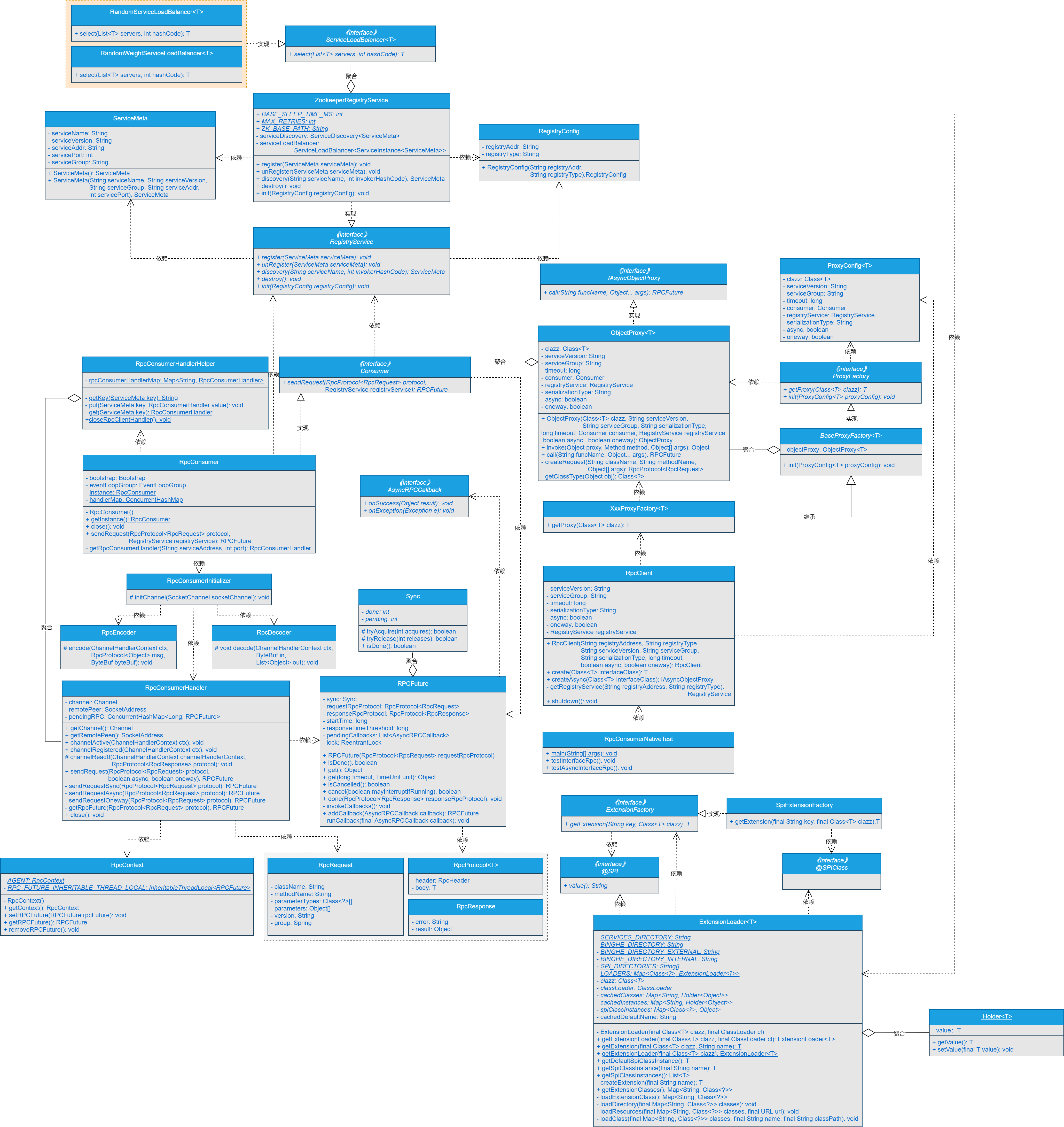
# 核心类实现关系
基于SPI扩展加权随机算法负载均衡策略的核心类关系如图43-2所示。
# 查看完整文章
加入冰河技术 (opens new window)知识星球,解锁完整技术文章与完整代码
