《高性能SQL引擎》SQL引擎设计-第01节:高性能SQL引擎SQL构建器设计与实现
作者:冰河
星球:http://m6z.cn/6aeFbs
博客:https://binghe.site
文章汇总:https://binghe.site/md/all/all.html
源码获取地址:https://t.zsxq.com/0dhvFs5oR
沉淀,成长,突破,帮助他人,成就自我。
- 本节难度:★★☆☆☆
- 本节重点:对高性能SQL引擎的SQL构建器进行设计与实现,从全局视角了解高性能SQL引擎的设计和架构思想,并能够将其灵活应用到自身实际项目中。
大家好,我是冰河~~
高性能SQL引擎最基础和最核心的功能就是通过JSON模板或者直接创建对象组合动态生成SQL,不再依赖各种实体模型来接收和传递数据。同时,高性能SQL引擎自身会设计和实现通用的数据模型。要想将这些通用的数据模型构建成通用的JSON模板或者创建对象组合动态SQL,则需要为高性能SQL引擎设计和实现专门的SQL构建器。
一、前言
截止到目前,我们已经明确了高性能SQL引擎的需求和流程,并且对高性能SQL引擎的方案目标、总体架构设计和内部执行流程进行了总体介绍,并且已经对高性能SQL引擎的通用化落地方案进行了详细的阐述。同时,在通用模型设计篇章,对高性能SQL引擎的通用数据模板和通用数据模型等进行了设计与实现。接下来,我们就需要思考如何设计和实现SQL构建器将这些通用的数据模型构建成通用的JSON模板或者创建对象组合动态SQL。
二、本节诉求
对高性能SQL引擎的SQL构建器进行设计与实现,从全局视角了解高性能SQL引擎的设计和架构思想,并能够将其灵活应用到自身实际项目中。
三、SQL构建器设计
SQL构建器在整体流程上会由SQL引擎进行驱动执行,并且SQL构建器会按照设计好的流程执行生成SQL的逻辑,如图1-1所示。
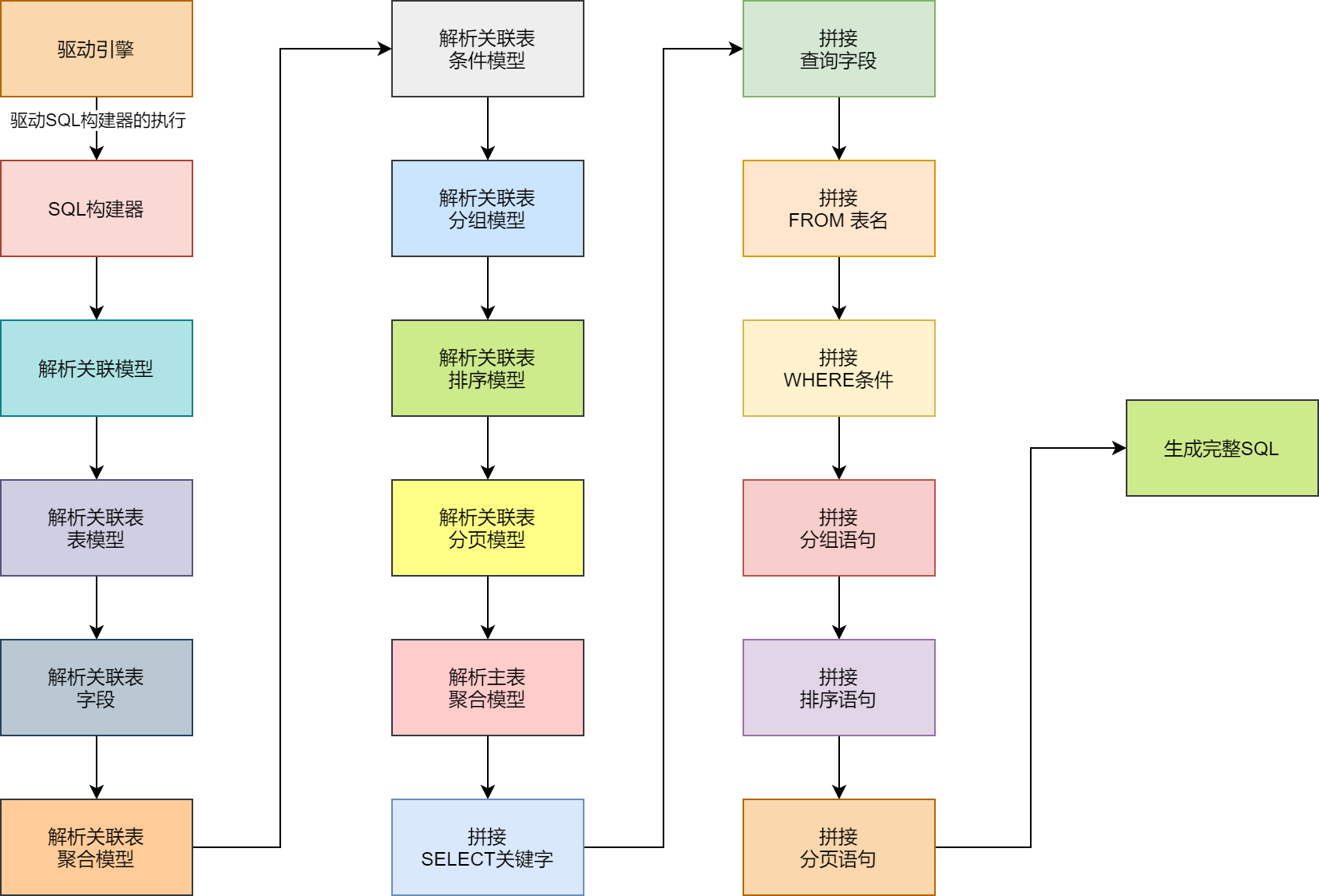
可以看到,SQL构建器在SQL引擎的驱动下,经过一系列设计好的流程,将各个通用模型,包括:表模型、分组与聚合模型、关联模型、条件模型、分页模型和排序模型等,进行解析和拼接,最终生成我们想要的完整SQL语句。
四、SQL构建器实现
由于SQL构建器的代码实现相对比较复杂,代码量较多,这里,只给出SQL构建器的一部分代码实现,完整的实现代码,大家可以到本节对应的代码分支进行查看。
(1)实现核心成员变量
对于SQL构建器来说,在生成SQL的过程中,需要将一些中间状态或者中间碎片化的SQL语句保存在成员变量中,所以需要为SQL构建器定义一些成员变量。
源码详见:io.binghe.sql.plugin.builder.SqlBuilder。
查看完整文章
加入冰河技术知识星球,解锁完整技术文章、小册、视频与完整代码
