《Spring核心技术》第02章-驱动型注解:深度解析@ComponentScans注解与@ComponentScan注解
作者:冰河
星球:http://m6z.cn/6aeFbs
博客:https://binghe.site
文章汇总:https://binghe.site/md/all/all.html
源码地址:https://github.com/binghe001/spring-annotation-book/tree/master/spring-annotation-chapter-02
沉淀,成长,突破,帮助他人,成就自我。
大家好,我是冰河~~
本章难度:★★★☆☆
本章重点:进一步了解@ComponentScans注解与@ComponentScan注解的使用方法和如何避免踩坑,并在源码级别彻底理解和吃透@ComponentScans注解与@ComponentScan注解的执行流程。
一、学习指引
想成为秃顶的资深工程师,关于@ComponentScans注解与@ComponentScan注解,不能只停留在表面!
翻开Spring的源码找到@ComponentScan注解的源码,发现注解类上赫然标注着Since: 3.1字样。也就是说,@ComponentScan注解是从Spring的3.1版本开始提供的。在@ComponentScan注解上,标注了一个@Repeatable注解,@Repeatable注解的属性值为ComponentScans.class。再次翻看下@ComponentScans注解的源码,类上标注着Since: 4.3字样。也就是说,@ComponentScans注解是从Spring4.3版本开始提供的。@ComponentScans注解就相当于是@ComponentScan注解的一个数组,在@ComponentScans注解中可以多次使用@ComponentScan注解来扫描不同的包路径。
如果你只想做一个天天加班的CRUD的程序员,掌握上述的基本知识就够了。CRUD操作不需要你对@ComponentScans注解与@ComponentScan注解有多么深入的了解。但是,如果你想对Spring的源码有进一步的了解和认识,想熟悉Spring核心源码的执行流程,想成为一名合格的架构师或技术专家,只了解上述@ComponentScans注解与@ComponentScan注解最基本的知识点是远远不够的。
二、注解说明
@ComponentScans注解与@ComponentScan注解的一点点说明!
@ComponentScans注解可以看作是@ComponentScan注解的一个数组,在@ComponentScans注解中可以多次标注@ComponentScan注解。
@ComponentScan注解最核心的功能就是Spring IOC容器在刷新的时候会扫描对应包下标注了@Component注解、@Configuration注解、@Repository注解、@Service注解和@Controller等等注解的类,生成扫描到的类的Bean定义信息,整体流程与注册ConfigurationClassPostProcessor类的Bean定义信息的流程基本一致,最终都会将其保存到BeanFactory中的beanDefinitionMap中。
2.1 注解源码
本节,主要是对@ComponentScans注解和@ComponentScan注解的源码进行简单的剖析。
2.1.1 @ComponentScans注解源码
源码详见:org.springframework.context.annotation.ComponentScans,如下所示。
/***
* @author Juergen Hoeller
* @since 4.3
* @see ComponentScan
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
public @interface ComponentScans {
ComponentScan[] value();
}
可以看到,@ComponentScans注解的源码还是比较简单的,在@ComponentScans注解中存在一个ComponentScan[]数组类型的value属性,说明@ComponentScans注解的属性可以存放一个@ComponentScan注解类型的数组,可以在ComponentScans注解中多次添加@ComponentScan注解。从@ComponentScans注解的源码还可以看出,@ComponentScans注解从Spring 4.3版本开始提供。
2.1.2 @ComponentScan注解源码
@ComponentScan注解的源码是本章分析的重点内容,@ComponentScan注解的源码详见:org.springframework.context.annotation.ComponentScan,如下所示。
/*
* @author Chris Beams
* @author Juergen Hoeller
* @author Sam Brannen
* @since 3.1
* @see Configuration
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Repeatable(ComponentScans.class)
public @interface ComponentScan {
@AliasFor("basePackages")
String[] value() default {};
@AliasFor("value")
String[] basePackages() default {};
Class<?>[] basePackageClasses() default {};
Class<? extends BeanNameGenerator> nameGenerator() default BeanNameGenerator.class;
Class<? extends ScopeMetadataResolver> scopeResolver() default AnnotationScopeMetadataResolver.class;
ScopedProxyMode scopedProxy() default ScopedProxyMode.DEFAULT;
String resourcePattern() default ClassPathScanningCandidateComponentProvider.DEFAULT_RESOURCE_PATTERN;
boolean useDefaultFilters() default true;
Filter[] includeFilters() default {};
Filter[] excludeFilters() default {};
boolean lazyInit() default false;
@Retention(RetentionPolicy.RUNTIME)
@Target({})
@interface Filter {
FilterType type() default FilterType.ANNOTATION;
@AliasFor("classes")
Class<?>[] value() default {};
@AliasFor("value")
Class<?>[] classes() default {};
String[] pattern() default {};
}
}
可以看到,Spring从3.1版本开始提供@ComponentScan注解,@ComponentScan注解中还有一个内部注解@Filter。
@ComponentScan注解中的每个属性的含义如下所示。
- value:作用同basePackages属性,String[]数组类型,指定要扫描的包名。如果指定了要扫描的包名,则Spring会扫描指定的包及其子包下的所有类。
- basePackages:作用同value属性,String[]数组类型,指定要扫描的包名。如果指定了要扫描的包名,则Spring会扫描指定的包及其子包下的所有类。
- basePackageClasses:Class
<?>[]数组类型,指定要扫描的类的Class对象。 - nameGenerator:Class
<? extends BeanNameGenerator>类型,指定扫描类时,向IOC注入Bean对象时的命名规则。 - scopeResolver:Class
<? extends ScopeMetadataResolver>类型,扫描类时,用于处理并转换符合条件的Bean的作用范围。 - scopedProxy:ScopedProxyMode类型,指定生成Bean对象时的代理方式,默认的代理方法是DEFAULT,也就是不使用代理。关于ScopedProxyMode的更多详细的内容,参见2.1.3节。
- resourcePattern:String类型,用于指定扫描的文件类型,默认是扫描指定包下的
**/*.class。 - useDefaultFilters:boolean类型,是否自动检测@Component @Repository @Service @Controller注解,默认是true。
- includeFilters:Filter[]数组类型,自定义组件扫描过滤规则,符合过滤规则的类的Bean定义信息会被注册到IOC容器中。includeFilters表示只包含对应的规则,当使用includeFilters()来指定只包含哪些注解标注的类时,需要禁用默认的过滤规则,也就是需要将useDefaultFilters属性设置为false。并且,除了符合过滤规则的类外,Spring内置的如下名称的类的Bean定义信息注册到IOC容器时不受过滤规则限制,如下所示。
org.springframework.context.annotation.internalConfigurationAnnotationProcessor
org.springframework.context.annotation.internalAutowiredAnnotationProcessor
org.springframework.context.event.internalEventListenerProcessor
org.springframework.context.event.internalEventListenerFactory
- excludeFilters:Filter[]数组类型,自定义组件扫描过滤规则,excludeFilters表示排除使用对应的规则,符合过滤规则的类的Bean定义信息不会被注册到IOC容器中。
- lazyInit:boolean类型,从Spring4.1版本开始提供,表示Spring扫描组件时是否采用懒加载 ,默认false,表示不开启懒加载。
@Filter注解中的每个属性的含义如下所示。
- type:FilterType类型,表示过滤规则的类型。关于FilterType的更多详细的内容,参见2.1.4节。
- value:Class
<?>[]数组类型,过滤符合规则的类,作用同classes属性。 - classes:Class
<?>[]数组类型,过滤符合规则的类,作用同value属性。 - pattern:如果FilterType取值为ASPECTJ,则此属性表示ASPECTJ表达式。
2.1.3 ScopedProxyMode枚举类源码
ScopedProxyMode枚举类表示Spring指定生成Bean对象时的代理方式,源码详见:org.springframework.context.annotation.ScopedProxyMode。
/*
* @author Mark Fisher
* @since 2.5
* @see ScopeMetadata
*/
public enum ScopedProxyMode {
DEFAULT,
NO,
INTERFACES,
TARGET_CLASS
}
ScopedProxyMode类是从Spring 2.5版本开始提供的枚举类,每个属性的含义如下所示。
- DEFAULT:默认的代理方式,也就是不使用代理,除非在component-scan级别使用了不同的配置。
- NO:不使用代理。
- INTERFACES:基于JDK动态代理实现接口代理对象。
- TARGET_CLASS:基于CGLib动态代理创建类代理对象。
2.1.4 FilterType枚举类源码
FilterType枚举类表示Spring扫描类时的过滤类型,源码详见:org.springframework.context.annotation.FilterType,如下所示。
/*
* @author Mark Fisher
* @author Juergen Hoeller
* @author Chris Beams
* @since 2.5
*/
public enum FilterType {
ANNOTATION,
ASSIGNABLE_TYPE,
ASPECTJ,
REGEX,
CUSTOM
}
FilterType类是Spring2.5版本开始提供的枚举类,每个属性的含义如下所示。
- ANNOTATION:按照注解进行过滤。
- ASSIGNABLE_TYPE:按照给定的类型进行过滤。
- ASPECTJ:按照ASPECTJ表达式进行过滤。
- REGEX:按照正则表达式进行过滤。
- CUSTOM:按照自定义规则进行过滤,使用自定义过滤规则时,自定义的过滤器需要实现org.springframework.core.type.filter.TypeFilter接口。
在FilterType枚举类中,ANNOTATION和ASSIGNABLE_TYPE是比较常用的,ASPECTJ和REGEX不太常用,如果FilterType枚举类中的类型无法满足日常开发需求时,可以通过实现org.springframework.core.type.filter.TypeFilter接口来自定义过滤规则,此时,将@Filter中的type属性设置为FilterType.CUSTOM,classes属性设置为自定义规则的类对应的Class对象。
2.2 注解使用场景
使用Spring的注解开发应用程序时,如果需要将标注了Spring注解的类注入到IOC容器中,就需要使用@ComponentScan注解来扫描指定包下的类。同时,在Spring4.3版本开始,提供了@ComponentScans注解,在@ComponentScans注解中,支持配置多个@ComponentScan注解来扫描不同的包,配置不同的过滤规则。
三、使用案例
整个案例来玩玩儿吧!
3.1 案例描述
使用自定义过滤规则实现Spring扫描指定包下的类时,使得名称中含有 componentScanConfig 字符串的类符合过滤规则。
3.2 案例实现
整个案例实现的步骤总体如下所示。
(1)新建自定义过滤规则类ComponentScanFilter
ComponentScanFilter类的源码详见:spring-annotation-chapter-02工程下的io.binghe.spring.annotation.chapter02.componentscan.filter.ComponentScanFilter,如下所示。
public class ComponentScanFilter implements TypeFilter {
@Override
public boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory) throws IOException {
//获取当前正在扫描的类的信息
ClassMetadata classMetadata = metadataReader.getClassMetadata();
//获取当前正在扫描的类名
String className = classMetadata.getClassName();
return className.contains("componentScanConfig");
}
}
可以看到,自定义过滤规则ComponentScanFilter类实现了TypeFilter接口,并覆写了match()方法,match()方法中的核心逻辑就是:如果类的名称中含有componentScanConfig字符串,符合过滤规则,返回true,否则,返回false。
(2)新建配置类ComponentScanConfig
ComponentScanConfig类的源码详见:spring-annotation-chapter-02工程下的io.binghe.spring.annotation.chapter02.componentscan.config.ComponentScanConfig,如下所示。
@Configuration
@ComponentScan(value = "io.binghe.spring.annotation.chapter02", includeFilters = {
@Filter(type = FilterType.CUSTOM, classes = {ComponentScanFilter.class})
}, useDefaultFilters = false)
public class ComponentScanConfig {
}
可以看到,在ComponentScanConfig类上标注了@Configuration注解,说明ComponentScanConfig类是Spring的配置类。在标注的@ComponentScan注解中指定了要扫描的包名,使用只包含的过滤规则,并采用自定义过滤规则。
此时,需要注意的是,需要将是否使用默认的过滤规则设置为false。
(3)新建测试类ComponentScanTest
ComponentScanTest类的源码详见:spring-annotation-chapter-02工程下的io.binghe.spring.annotation.chapter02.componentscan.ComponentScanTest,如下所示。
public class ComponentScanTest {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(ComponentScanConfig.class);
String[] names = context.getBeanDefinitionNames();
Arrays.stream(names).forEach(System.out::println);
}
}
可以看到,在ComponentScanTest类中,在AnnotationConfigApplicationContext类的构造方法中传入ComponentScanConfig类的Class对象创建IOC容器,并将其赋值给context局部变量。通过context局部变量的getBeanDefinitionNames()方法获取所有的Bean定义名称,随后遍历这些Bean定义名称进行打印。
3.3 案例测试
本案例中,在@ComponentScan注解中使用了includeFilters过滤规则,并且使用的是自定义过滤规则,符合过滤规则的是名称中含有 componentScanConfig 字符串的类。另外,Spring中内置的Processor类和Factory类的Bean定义信息注册到IOC容器时,不受过滤规则限制。
运行ComponentScanTest类输出的结果信息如下所示。
org.springframework.context.annotation.internalConfigurationAnnotationProcessor
org.springframework.context.annotation.internalAutowiredAnnotationProcessor
org.springframework.context.event.internalEventListenerProcessor
org.springframework.context.event.internalEventListenerFactory
componentScanConfig
可以看到,从IOC容器中获取的Bean的类定义信息的名称中可以看出,除了名称中包含componentScanConfig字符串的类符合过滤规则外,Spring内置的Processor类和Factory类不受过滤规则限制,其类的Bean定义信息都注册到了IOC容器中。
3.4 其他应用案例
1.扫描时排除注解标注的类
排除@Controller、@Service和@Repository注解,可以在配置类上通过@ComponentScan注解的excludeFilters()属性实现,如下所示。
@ComponentScan(value = "io.binghe.spring.annotation.chapter02", excludeFilters = {
@Filter(type = FilterType.ANNOTATION, classes = {Controller.class, Service.class, Repository.class})
})
2.扫描时只包含注解标注的类
可以使用ComponentScan注解类的includeFilters()属性来指定Spring在进行包扫描时,只包含哪些注解标注的类。如果使用includeFilters()属性来指定只包含哪些注解标注的类时,需要禁用默认的过滤规则。
例如,只包含@Controller注解标注的类,可以在配置类上添加@ComponentScan注解,设置只包含@Controller注解标注的类,并禁用默认的过滤规则,如下所示。
@ComponentScan(value = "io.binghe.spring.annotation.chapter02", includeFilters = {
@Filter(type = FilterType.ANNOTATION, classes = {Controller.class})
}, useDefaultFilters = false)
3.重复注解
在Java8中@ComponentScan注解是一个重复注解,可以在一个配置类上重复使用这个注解,如下所示。
@ComponentScan(value = "io.binghe.spring.annotation.chapter02", includeFilters = {
@Filter(type = FilterType.ANNOTATION, classes = {Controller.class})
}, useDefaultFilters = false)
@ComponentScan(value = "io.binghe.spring.annotation.chapter02", includeFilters = {
@Filter(type = FilterType.ANNOTATION, classes = {Service.class})
}, useDefaultFilters = false)
如果使用的是Java8之前的版本,就不能直接在配置类上写多个@ComponentScan注解了。此时,可以在配置类上使用@ComponentScans注解,如下所示。
@ComponentScans(value = {
@ComponentScan(value = "io.binghe.spring.annotation.chapter02", includeFilters = {
@Filter(type = FilterType.ANNOTATION, classes = {Controller.class})
}, useDefaultFilters = false),
@ComponentScan(value = "io.binghe.spring.annotation.chapter02", includeFilters = {
@Filter(type = FilterType.ANNOTATION, classes = {Service.class})
}, useDefaultFilters = false)
})
总结:可以使用@ComponentScan注解来指定Spring扫描哪些包,可以使用excludeFilters()指定扫描时排除哪些组件,也可以使用includeFilters()指定扫描时只包含哪些组件。当使用includeFilters()指定只包含哪些组件时,需要禁用默认的过滤规则。
4.扫描时按照注解进行过滤
使用@ComponentScan注解进行包扫描时,按照注解只包含标注了@Controller注解的组件,如下所示。
@ComponentScan(value = "io.binghe.spring.annotation.chapter02", includeFilters = {
@Filter(type = FilterType.ANNOTATION, classes = {Controller.class})
}, useDefaultFilters = false)
5.扫描时按照指定的类型进行过滤
使用@ComponentScan注解进行包扫描时,按照给定的类型只包含DemoService类(接口)或其子类(实现类或子接口)的组件,如下所示。
@ComponentScan(value = "io.binghe.spring.annotation.chapter02", includeFilters = {
@Filter(type = FilterType.ASSIGNABLE_TYPE, classes = {DemoService.class})
}, useDefaultFilters = false)
此时,只要是DemoService类型的组件,都会被加载到容器中。也就是说:当DemoService是一个Java类时,DemoService类及其子类都会被加载到Spring容器中;当DemoService是一个接口时,其子接口或实现类都会被加载到Spring容器中。
6.扫描时按照ASPECTJ表达式进行过滤
使用@ComponentScan注解进行包扫描时,按照ASPECTJ表达式进行过滤,如下所示。
@ComponentScan(value = "io.binghe.spring.annotation.chapter02", includeFilters = {
@Filter(type = FilterType.ASPECTJ, classes = {AspectJTypeFilter.class})
}, useDefaultFilters = false)
其中,AspectJTypeFilter类就是自定义的ASPECTJ表达式的过滤器类。
7.扫描时按照正则表达式进行过滤
使用@ComponentScan注解进行包扫描时,按照正则表达式进行过滤,如下所示。
@ComponentScan(value = "io.binghe.spring.annotation.chapter02", includeFilters = {
@Filter(type = FilterType.REGEX, classes = {RegexPatternTypeFilter.class})
}, useDefaultFilters = false)
其中,RegexPatternTypeFilter类就是自定义的正则表达式的过滤器类。
8.扫描时按照自定义规则进行过滤
如果实现自定义规则进行过滤时,自定义规则的类必须是org.springframework.core.type.filter.TypeFilter接口的实现类。
例如,按照自定义规则进行过滤,首先,需要创建一个org.springframework.core.type.filter.TypeFilter接口的实现类BingheTypeFilter,如下所示。
public class BingheTypeFilter implements TypeFilter {
@Override
public boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory) throws IOException {
return false;
}
}
当实现TypeFilter接口时,需要实现TypeFilter接口中的match()方法,match()方法的返回值为boolean类型。当返回true时,表示符合过滤规则,会将类的Bean定义信息注册到IOC容器中;当返回false时,表示不符合过滤规则,对应的类的Bean定义信息不会注册到IOC容器中。
接下来,使用@ComponentScan注解进行如下配置。
@ComponentScan(value = "io.binghe.spring.annotation.chapter02", includeFilters = {
@Filter(type = FilterType.CUSTOM, classes = {BingheTypeFilter.class})
}, useDefaultFilters = false)
四、源码时序图
结合时序图理解源码会事半功倍,你觉得呢?
本节,就以源码时序图的方式,直观的感受下@ComponentScans注解与@ComponentScan注解在Spring源码层面的执行流程。@ComponentScans注解与@ComponentScan注解在Spring源码层面的执行流程如图2-1~2-3所示。
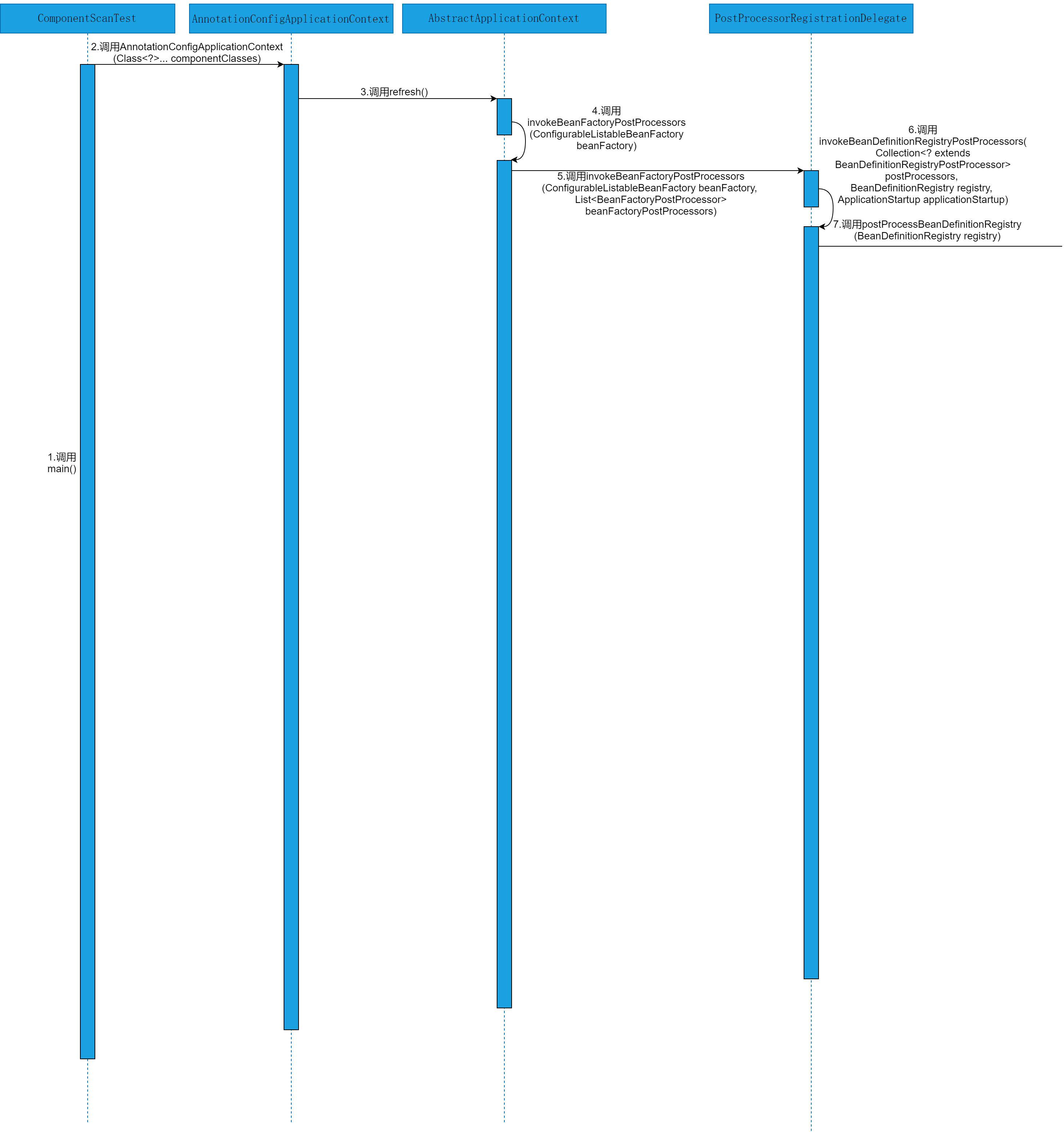
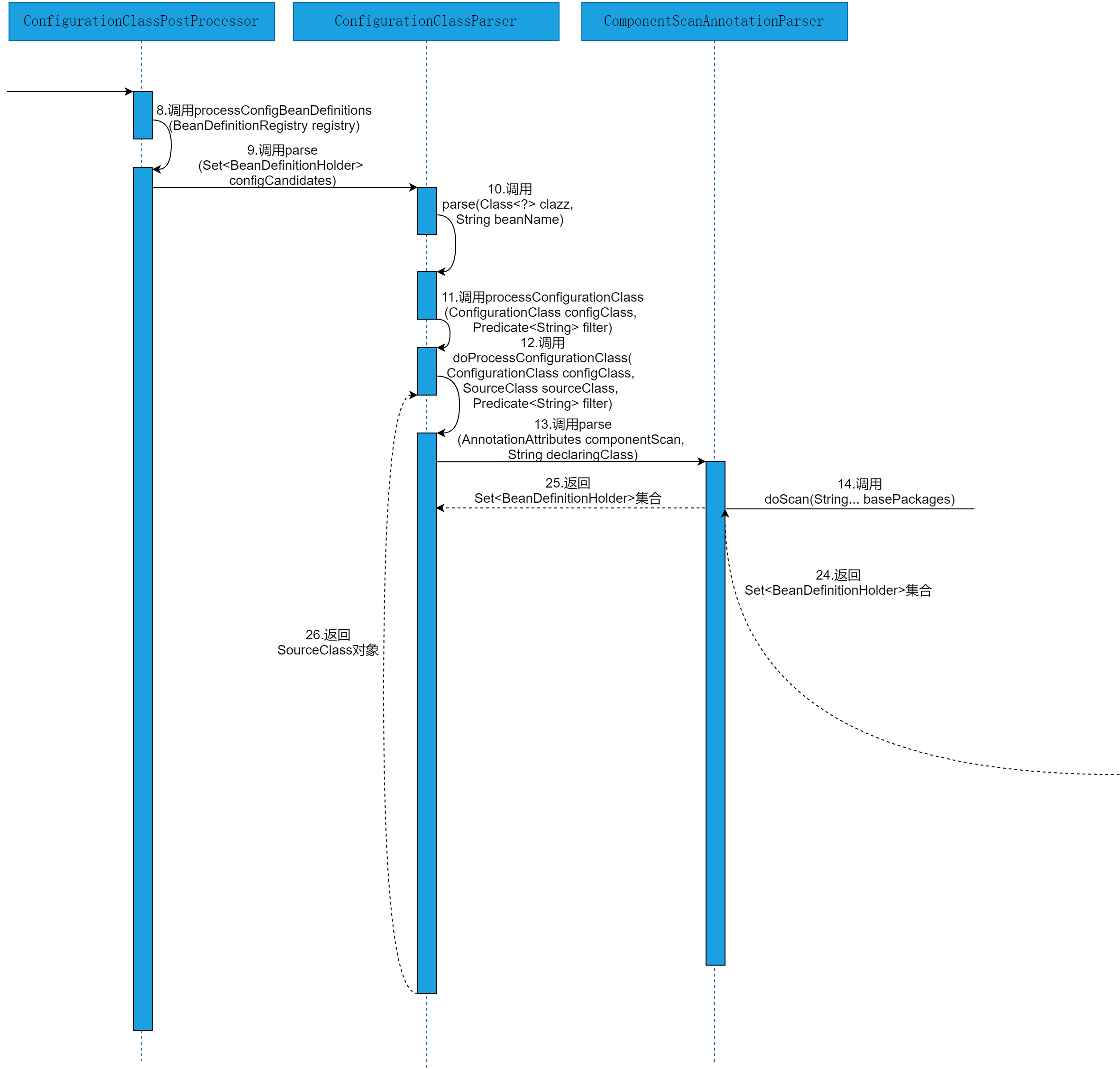
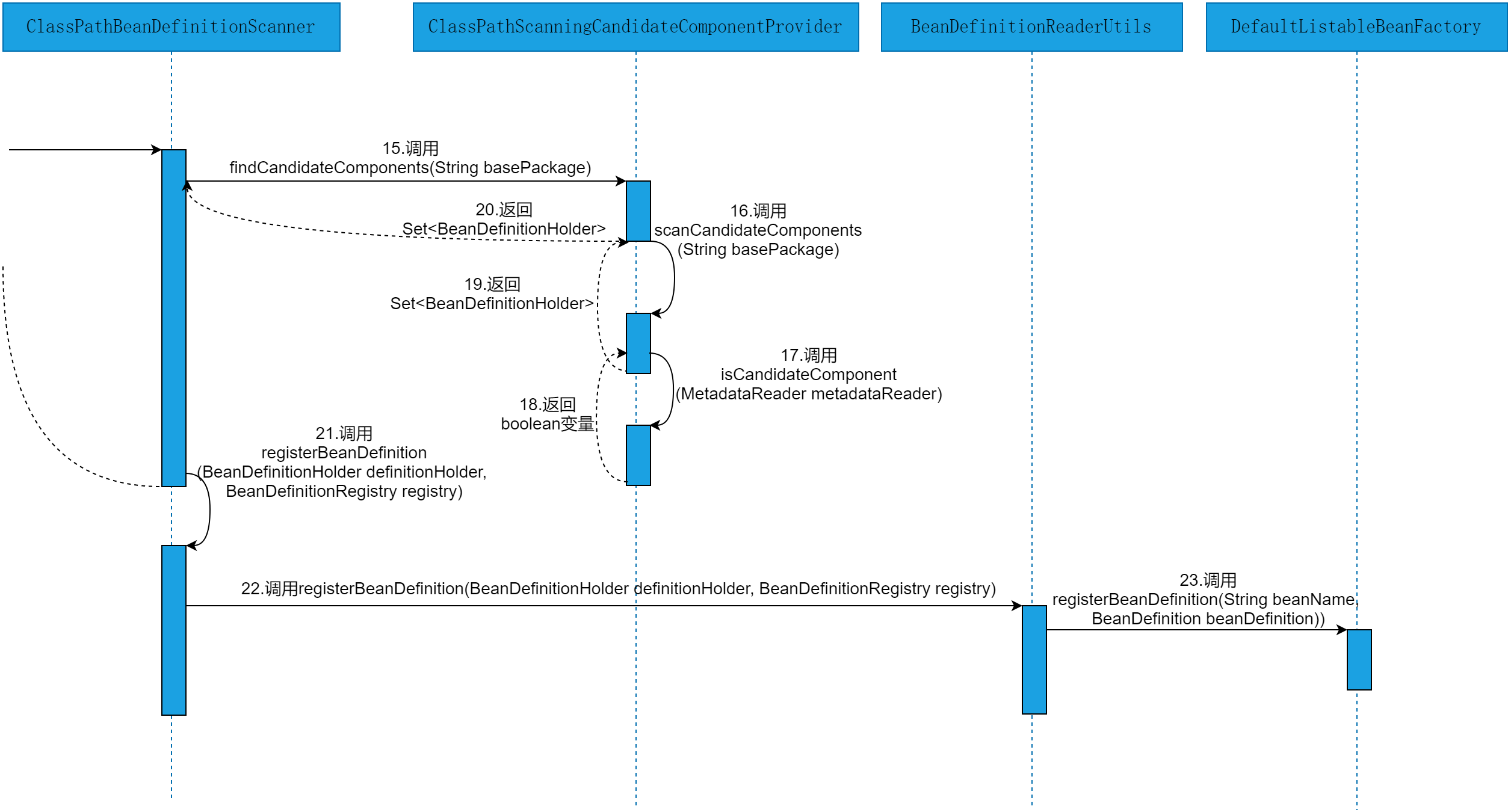
由图2-1~2-3可以看出,解析@ComponentScans注解与@ComponentScan注解在Spring源码中的执行流程,会涉及到ComponentScanTest类、AnnotationConfigApplicationContext类、AbstractApplicationContext类、PostProcessorRegistrationDelegate类、ConfigurationClassPostProcessor类、ConfigurationClassParser类、ComponentScanAnnotationParser类、ClassPathBeanDefinitionScanner类、ClassPathScanningCandidateComponentProvider类、BeanDefinitionReaderUtils类和DefaultListableBeanFactory类等。具体的源码执行细节参见源码解析部分。
五、源码解析
源码时序图整清楚了,那就整源码解析呗!
@ComponentScans注解与@ComponentScan注解在Spring源码中的执行流程,结合源码执行的时序图,会理解的更加深刻。
(1)运行案例程序启动类
案例程序启动类源码详见:spring-annotation-chapter-02工程下的io.binghe.spring.annotation.chapter02.componentscan.ComponentScanTest,运行ComponentScanTest类的main()方法。
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(ComponentScanConfig.class);
String[] names = context.getBeanDefinitionNames();
Arrays.stream(names).forEach(System.out::println);
}
可以看到,在ComponentScanTest类的main()方法中调用了AnnotationConfigApplicationContext类的构造方法,并传入了ComponentScanConfig类的Class对象来创建IOC容器。接下来,会进入AnnotationConfigApplicationContext类的构造方法。
(2)解析AnnotationConfigApplicationContext类的AnnotationConfigApplicationContext(Class<?>... componentClasses)构造方法
源码详见:org.springframework.context.annotation.AnnotationConfigApplicationContext#AnnotationConfigApplicationContext(Class<?>... componentClasses)。
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
this();
register(componentClasses);
refresh();
}
可以看到,在上述构造方法中,调用了refresh()方法来刷新IOC容器。
(3)解析AbstractApplicationContext类的refresh()方法
源码详见:org.springframework.context.support.AbstractApplicationContext#refresh()。
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
//############省略其他代码##############
try {
//############省略其他代码##############
invokeBeanFactoryPostProcessors(beanFactory);
//############省略其他代码##############
}catch (BeansException ex) {
//############省略其他代码##############
}finally {
//############省略其他代码##############
}
}
}
refresh()方法是Spring中一个非常重要的方法,很多重要的功能和特性都是通过refresh()方法进行注入的。可以看到,在refresh()方法中,调用了invokeBeanFactoryPostProcessors()方法。
(4)解析AbstractApplicationContext类的invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory)方法
源码详见:org.springframework.context.support.AbstractApplicationContext#invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory)。
protected void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory) {
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
if (!NativeDetector.inNativeImage() && beanFactory.getTempClassLoader() == null && beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
}
可以看到,在AbstractApplicationContext类的invokeBeanFactoryPostProcessors()方法中调用了PostProcessorRegistrationDelegate类的invokeBeanFactoryPostProcessors()方法。
(5)解析PostProcessorRegistrationDelegate类的invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors)方法
源码详见:org.springframework.context.support.PostProcessorRegistrationDelegate#invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors)。
由于方法的源码比较长,这里,只关注当前最核心的逻辑,如下所示。
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
//############省略其他代码##############
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());
currentRegistryProcessors.clear();
// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());
currentRegistryProcessors.clear();
// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());
currentRegistryProcessors.clear();
}
//############省略其他代码##############
}
可以看到,在PostProcessorRegistrationDelegate类的invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors)方法中,BeanDefinitionRegistryPostProcessor的实现类在执行逻辑上会有先后顺序,并且最终都会调用invokeBeanDefinitionRegistryPostProcessors()方法。
(6)解析PostProcessorRegistrationDelegate类的invokeBeanDefinitionRegistryPostProcessors(Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry, ApplicationStartup applicationStartup)方法
源码详见:org.springframework.context.support.PostProcessorRegistrationDelegate#invokeBeanDefinitionRegistryPostProcessors(Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry, ApplicationStartup applicationStartup)。
private static void invokeBeanDefinitionRegistryPostProcessors(
Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry, ApplicationStartup applicationStartup) {
for (BeanDefinitionRegistryPostProcessor postProcessor : postProcessors) {
StartupStep postProcessBeanDefRegistry = applicationStartup.start("spring.context.beandef-registry.post-process")
.tag("postProcessor", postProcessor::toString);
postProcessor.postProcessBeanDefinitionRegistry(registry);
postProcessBeanDefRegistry.end();
}
}
可以看到,在invokeBeanDefinitionRegistryPostProcessors()方法中,会循环遍历postProcessors集合中的每个元素,调用postProcessBeanDefinitionRegistry()方法注册Bean的定义信息。
(7)解析ConfigurationClassPostProcessor类的postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry)方法
源码详见:org.springframework.context.annotation.ConfigurationClassPostProcessor#postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry)。
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
//##########省略其他代码###################
processConfigBeanDefinitions(registry);
}
可以看到,在postProcessBeanDefinitionRegistry()方法中,会调用processConfigBeanDefinitions()方法。
(8)解析ConfigurationClassPostProcessor类的processConfigBeanDefinitions(BeanDefinitionRegistry registry)方法
源码详见:org.springframework.context.annotation.ConfigurationClassPostProcessor#processConfigBeanDefinitions(BeanDefinitionRegistry registry)。
这里,重点关注方法中的如下逻辑。
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
//############省略其他代码#################
// Parse each @Configuration class
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
do {
StartupStep processConfig = this.applicationStartup.start("spring.context.config-classes.parse");
parser.parse(candidates);
parser.validate();
//############省略其他代码#################
}
while (!candidates.isEmpty());
//############省略其他代码#################
}
可以看到,在processConfigBeanDefinitions()方法中,创建了一个ConfigurationClassParser类型的对象parser,并且调用了parser的parse()方法来解析类的配置信息。
(9)解析ConfigurationClassParser类的parse(Set<BeanDefinitionHolder> configCandidates)方法
源码详见:org.springframework.context.annotation.ConfigurationClassParser#parse(Set<BeanDefinitionHolder> configCandidates)。
public void parse(Set<BeanDefinitionHolder> configCandidates) {
for (BeanDefinitionHolder holder : configCandidates) {
BeanDefinition bd = holder.getBeanDefinition();
try {
if (bd instanceof AnnotatedBeanDefinition) {
parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
}
else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {
parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
}
else {
parse(bd.getBeanClassName(), holder.getBeanName());
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex);
}
}
this.deferredImportSelectorHandler.process();
}
可以看到,在ConfigurationClassParser类的parse(Set<BeanDefinitionHolder> configCandidates)方法中,调用了类中的另一个parse()方法。
(10)解析ConfigurationClassParser类的parse(AnnotationMetadata metadata, String beanName)方法
源码详见:org.springframework.context.annotation.ConfigurationClassParser#parse(AnnotationMetadata metadata, String beanName)
protected final void parse(AnnotationMetadata metadata, String beanName) throws IOException {
processConfigurationClass(new ConfigurationClass(metadata, beanName), DEFAULT_EXCLUSION_FILTER);
}
可以看到,上述parse()方法的实现比较简单,直接调用了processConfigurationClass()方法。
(11)解析ConfigurationClassParser类的processConfigurationClass(ConfigurationClass configClass, Predicate<String> filter)方法
源码详见:org.springframework.context.annotation.ConfigurationClassParser#processConfigurationClass(ConfigurationClass configClass, Predicate<String> filter)。
protected void processConfigurationClass(ConfigurationClass configClass, Predicate<String> filter) throws IOException {
//###############省略其他代码####################
SourceClass sourceClass = asSourceClass(configClass, filter);
do {
sourceClass = doProcessConfigurationClass(configClass, sourceClass, filter);
}
while (sourceClass != null);
this.configurationClasses.put(configClass, configClass);
}
可以看到,在processConfigurationClass()方法中,会通过do-while()循环获取配置类和其父类的注解信息,SourceClass类中会封装配置类上注解的详细信息。在在processConfigurationClass()方法中,调用了doProcessConfigurationClass()方法。
(12)解析ConfigurationClassParser类的doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)方法
源码详见:org.springframework.context.annotation.ConfigurationClassParser#doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)。
protected final SourceClass doProcessConfigurationClass(
ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)
throws IOException {
//##############省略其他代码################
// Process any @ComponentScan annotations
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
//##############省略其他代码################
// No superclass -> processing is complete
return null;
}
这里,只关注与@ComponentScan注解相关的逻辑,可以看到,在上述处理@ComponentScan注解的逻辑中,通过componentScanParser的parse()方法对@ComponentScan注解进行解析。
(13)解析ComponentScanAnnotationParser类的parse(AnnotationAttributes componentScan, String declaringClass)方法
源码详见:org.springframework.context.annotation.ComponentScanAnnotationParser#parse(AnnotationAttributes componentScan, String declaringClass)。
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, String declaringClass) {
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
scanner.setResourcePattern(componentScan.getString("resourcePattern"));
for (AnnotationAttributes includeFilterAttributes : componentScan.getAnnotationArray("includeFilters")) {
List<TypeFilter> typeFilters = TypeFilterUtils.createTypeFiltersFor(includeFilterAttributes, this.environment,
this.resourceLoader, this.registry);
for (TypeFilter typeFilter : typeFilters) {
scanner.addIncludeFilter(typeFilter);
}
}
for (AnnotationAttributes excludeFilterAttributes : componentScan.getAnnotationArray("excludeFilters")) {
List<TypeFilter> typeFilters = TypeFilterUtils.createTypeFiltersFor(excludeFilterAttributes, this.environment,
this.resourceLoader, this.registry);
for (TypeFilter typeFilter : typeFilters) {
scanner.addExcludeFilter(typeFilter);
}
}
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
Set<String> basePackages = new LinkedHashSet<>();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
return scanner.doScan(StringUtils.toStringArray(basePackages));
}
看到这里,大家是不是有一种豁然开朗的感觉,原来@ComponentScan注解是在这里解析的!!!!
可以看到,在parse()方法中,会创建一个ClassPathBeanDefinitionScanner类型的扫描器scanner,将@ComponentScan注解上配置的信息都设置到扫描器scanner中,最后调用扫描器scanner的doScan()方法进行扫描。
(14)解析ClassPathBeanDefinitionScanner类的doScan(String... basePackages)方法
源码详见:org.springframework.context.annotation.ClassPathBeanDefinitionScanner#doScan(String... basePackages)。
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
在doScan()方法中,会遍历传入的每个包路径,调用findCandidateComponents()方法来扫描带有注解(例如@Component注解)的类。
(15)解析ClassPathScanningCandidateComponentProvider类的findCandidateComponents(String basePackage)方法
源码详见:org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#findCandidateComponents(String basePackage)。
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
可以看到,Spring在扫描类时,会调用scanCandidateComponents()方法。
(16)解析ClassPathScanningCandidateComponentProvider类的scanCandidateComponents(String basePackage)方法
源码详见:org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#scanCandidateComponents(String basePackage)。
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
String filename = resource.getFilename();
if (filename != null && filename.contains(ClassUtils.CGLIB_CLASS_SEPARATOR)) {
// Ignore CGLIB-generated classes in the classpath
continue;
}
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
//################省略其他代码###################
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
可以看到,在scanCandidateComponents()方法中,会调用isCandidateComponent()方法来判断当前注解是不是要扫描的注解。
(17)解析ClassPathScanningCandidateComponentProvider类的isCandidateComponent(MetadataReader metadataReader)方法
源码详见:org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#isCandidateComponent(MetadataReader metadataReader)。
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return isConditionMatch(metadataReader);
}
}
return false;
}
可以看到,isCandidateComponent()方法的逻辑还是比较简单的,就是遍历匹配excludeFilters和includeFilters指定的规则。
优先匹配excludeFilters指定的规则,如果匹配excludeFilters指定的规则,直接返回false。接下来,匹配includeFilters指定的规则,匹配成功,则调用isConditionMatch()方法进行条件匹配。
其中,对于includeFilters而言,默认的过滤规则如下所示。
protected void registerDefaultFilters() {
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("jakarta.annotation.ManagedBean", cl)), false));
logger.trace("JSR-250 'jakarta.annotation.ManagedBean' found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Jakarta EE) not available - simply skip.
}
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("jakarta.inject.Named", cl)), false));
logger.trace("JSR-330 'jakarta.inject.Named' annotation found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
可以看到,对于includeFilters而言,默认的过滤规则会匹配@Component注解,JSR-250中的注解和JSR-330中的注解。
(18)回到ClassPathScanningCandidateComponentProvider类的scanCandidateComponents(String basePackage)方法
在ClassPathScanningCandidateComponentProvider类的scanCandidateComponents(String basePackage)方法中,会将标注了@Component注解,JSR-250中的注解和JSR-330中的注解的类信息封装成ScannedGenericBeanDefinition类对象,也就是类的Bean定义信息。
ScannedGenericBeanDefinition类的构造方法如下所示。
public ScannedGenericBeanDefinition(MetadataReader metadataReader) {
Assert.notNull(metadataReader, "MetadataReader must not be null");
this.metadata = metadataReader.getAnnotationMetadata();
setBeanClassName(this.metadata.getClassName());
setResource(metadataReader.getResource());
}
(19)回到ClassPathBeanDefinitionScanner类的doScan(String... basePackages)方法
在ClassPathBeanDefinitionScanner类的doScan(String... basePackages)方法中,会将扫描到的类的Bean定义信息注册到IOC容器中,如下代码片段所示。
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
可以看到,在doScan()方法中,会调用registerBeanDefinition()注册Bean定义信息。
(20)解析ClassPathBeanDefinitionScanner类的registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)方法
源码详见:org.springframework.context.annotation.ClassPathBeanDefinitionScanner#registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)。
protected void registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry) {
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, registry);
}
可以看到,在方法中直接调用了BeanDefinitionReaderUtils类的registerBeanDefinition()方法。
(21)解析BeanDefinitionReaderUtils类的registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)方法。
源码详见:org.springframework.beans.factory.support.BeanDefinitionReaderUtils#registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)。
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
//###########省略其他代码###################
}
可以看到,在上述代码中,会继续调用BeanDefinitionRegistry类型的对象registry的registerBeanDefinition()方法,将类的Bean定义信息注册到IOC容器。
(22)解析DefaultListableBeanFactory类的registerBeanDefinition(String beanName, BeanDefinition beanDefinition)方法
源码详见:org.springframework.beans.factory.support.DefaultListableBeanFactory#registerBeanDefinition(String beanName, BeanDefinition beanDefinition)。
@Override
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
//##############省略其他代码#################
BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);
if (existingDefinition != null) {
//##############省略其他代码#################
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
//##############省略其他代码#################
if (hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
removeManualSingletonName(beanName);
}
}
else {
// Still in startup registration phase
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
removeManualSingletonName(beanName);
}
this.frozenBeanDefinitionNames = null;
}
if (existingDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
else if (isConfigurationFrozen()) {
clearByTypeCache();
}
}
可以看到,Spring会将扫描到的标注了符合过滤规则的注解的类封装成对应的Bean定义信息,最终会将这些Bean定义信息注册到beanDefinitionMap中。这一点和第1章中,注册ConfigurationClassPostProcessor类的Bean定义信息有点类似。
好了,至此,@ComponentScans注解与@ComponentScan注解在Spring源码中的执行流程分析完毕。
六、总结
@ComponentScans注解与@ComponentScan注解讲完了,一起来总结下吧!
本章,主要对@ComponentScans注解与@ComponentScan注解进行了系统性的介绍。
首先,对@ComponentScans注解与@ComponentScan注解的源码和使用场景进行了简单的介绍。
随后,给出了使用@ComponentScan注解自定义过滤规则的案例,并简单列举了其他应用案例。
接下来,重点分析了@ComponentScans注解与@ComponentScan注解的源码时序图和源码执行流程。
七、思考
既然学完了,就开始思考几个问题吧?
- Spring扫描指定包的逻辑看起来挺复杂的,Spring为何会这样设计?
- 如果使用Spring的注解开发应用程序,配置类上不标注@ComponentScans注解与@ComponentScan注解,能扫描到哪些包下的类?能将标注了@Component注解的类注入的IOC容器吗?
- @ComponentScan注解中的basePackages属性或者value属性可以设置任意包名吗(前提是包存在)?
好了,今天就到这儿吧,我是冰河,我们下期见~~
星球服务
加入星球,你将获得:
1.项目学习:微服务入门必备的SpringCloud Alibaba实战项目、手写RPC项目—所有大厂都需要的项目【含上百个经典面试题】、深度解析Spring6核心技术—只要学习Java就必须深度掌握的框架【含数十个经典思考题】、Seckill秒杀系统项目—进大厂必备高并发、高性能和高可用技能。
2.框架源码:手写RPC项目—所有大厂都需要的项目【含上百个经典面试题】、深度解析Spring6核心技术—只要学习Java就必须深度掌握的框架【含数十个经典思考题】。
3.硬核技术:深入理解高并发系列(全册)、深入理解JVM系列(全册)、深入浅出Java设计模式(全册)、MySQL核心知识(全册)。
4.技术小册:深入理解高并发编程(第1版)、深入理解高并发编程(第2版)、从零开始手写RPC框架、SpringCloud Alibaba实战、冰河的渗透实战笔记、MySQL核心知识手册、Spring IOC核心技术、Nginx核心技术、面经手册等。
5.技术与就业指导:提供相关就业辅导和未来发展指引,冰河从初级程序员不断沉淀,成长,突破,一路成长为互联网资深技术专家,相信我的经历和经验对你有所帮助。
冰河的知识星球是一个简单、干净、纯粹交流技术的星球,不吹水,目前加入享5折优惠,价值远超门票。加入星球的用户,记得添加冰河微信:hacker_binghe,冰河拉你进星球专属VIP交流群。
星球重磅福利
跟冰河一起从根本上提升自己的技术能力,架构思维和设计思路,以及突破自身职场瓶颈,冰河特推出重大优惠活动,扫码领券进行星球,直接立减149元,相当于5折, 这已经是星球最大优惠力度!
领券加入星球,跟冰河一起学习《SpringCloud Alibaba实战》、《手撸RPC专栏》和《Spring6核心技术》,更有已经上新的《大规模分布式Seckill秒杀系统》,从零开始介绍原理、设计架构、手撸代码。后续更有硬核中间件项目和业务项目,而这些都是你升职加薪必备的基础技能。
100多元就能学这么多硬核技术、中间件项目和大厂秒杀系统,如果是我,我会买他个终身会员!
其他方式加入星球
- 链接 :打开链接 http://m6z.cn/6aeFbs 加入星球。
- 回复 :在公众号 冰河技术 回复 星球 领取优惠券加入星球。
特别提醒: 苹果用户进圈或续费,请加微信 hacker_binghe 扫二维码,或者去公众号 冰河技术 回复 星球 扫二维码加入星球。
星球规划
后续冰河还会在星球更新大规模中间件项目和深度剖析核心技术的专栏,目前已经规划的专栏如下所示。
中间件项目
- 《大规模分布式定时调度中间件项目实战(非Demo)》:全程手撸代码。
- 《大规模分布式IM(即时通讯)项目实战(非Demo)》:全程手撸代码。
- 《大规模分布式网关项目实战(非Demo)》:全程手撸代码。
- 《手写Redis》:全程手撸代码。
- 《手写JVM》全程手撸代码。
超硬核项目
- 《从零落地秒杀系统项目》:全程手撸代码,在阿里云实现压测(已上新)。
- 《大规模电商系统商品详情页项目》:全程手撸代码,在阿里云实现压测。
- 其他待规划的实战项目,小伙伴们也可以提一些自己想学的,想一起手撸的实战项目。。。
既然星球规划了这么多内容,那么肯定就会有小伙伴们提出疑问:这么多内容,能更新完吗?我的回答就是:一个个攻破呗,咱这星球干就干真实中间件项目,剖析硬核技术和项目,不做Demo。初衷就是能够让小伙伴们学到真正的核心技术,不再只是简单的做CRUD开发。所以,每个专栏都会是硬核内容,像《SpringCloud Alibaba实战》、《手撸RPC专栏》和《Spring6核心技术》就是很好的示例。后续的专栏只会比这些更加硬核,杜绝Demo开发。
小伙伴们跟着冰河认真学习,多动手,多思考,多分析,多总结,有问题及时在星球提问,相信在技术层面,都会有所提高。将学到的知识和技术及时运用到实际的工作当中,学以致用。星球中不少小伙伴都成为了公司的核心技术骨干,实现了升职加薪的目标。
联系冰河
加群交流
本群的宗旨是给大家提供一个良好的技术学习交流平台,所以杜绝一切广告!由于微信群人满 100 之后无法加入,请扫描下方二维码先添加作者 “冰河” 微信(hacker_binghe),备注:星球编号。

公众号
分享各种编程语言、开发技术、分布式与微服务架构、分布式数据库、分布式事务、云原生、大数据与云计算技术和渗透技术。另外,还会分享各种面试题和面试技巧。内容在 冰河技术 微信公众号首发,强烈建议大家关注。

视频号
定期分享各种编程语言、开发技术、分布式与微服务架构、分布式数据库、分布式事务、云原生、大数据与云计算技术和渗透技术。另外,还会分享各种面试题和面试技巧。

星球
加入星球 冰河技术,可以获得本站点所有学习内容的指导与帮助。如果你遇到不能独立解决的问题,也可以添加冰河的微信:hacker_binghe, 我们一起沟通交流。另外,在星球中不只能学到实用的硬核技术,还能学习实战项目!
关注 冰河技术公众号,回复 星球 可以获取入场优惠券。

