# 《Spring注解驱动开发》第35章:实现多数据源读写分离
# 写在前面
很多小伙伴私聊我说:最近他们公司的业务涉及到多个数据源的问题,问我Spring如何实现多数据源的问题。回答这个问题之前,首先需要弄懂什么是多数据源:多数据源就是在同一个项目中,会连接两个甚至多个数据存储,这里的数据存储可以是关系型数据库(比如:MySQL、SQL Server、Oracle),也可以非关系型数据库,比如:HBase、MongoDB、ES等。那么,问题来了,Spring能够实现多数据源吗?并且还要实现读者分离?答案是:必须的,这么强大的Spring,肯定能实现啊!别急,我们就一点点剖析、解决这些问题!
# 背景
我们一般应用对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,有一个思路就是说采用数据库集群的方案,
其中一个是主库,负责写入数据,我们称之为:写库;其它都是从库,负责读取数据,我们称之为:读库;
那么,对我们的要求是:
- 读库和写库的数据一致;
- 写数据必须写到写库;
- 读数据必须到读库;
# 方案
解决读写分离的方案有两种:应用层解决和中间件解决。
# 应用层解决
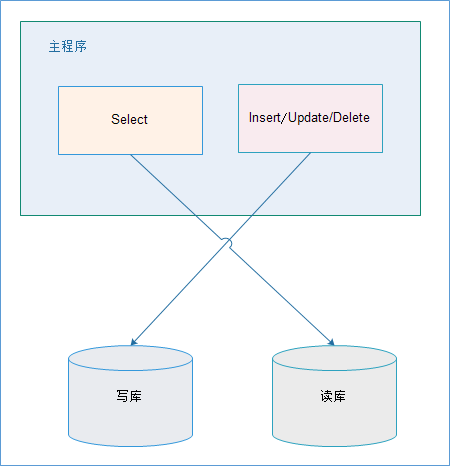
优点:
- 多数据源切换方便,由程序自动完成;
- 不需要引入中间件;
- 理论上支持任何数据库;
缺点:
- 由程序员完成,运维参与不到;
- 不能做到动态增加数据源;
# 中间件解决
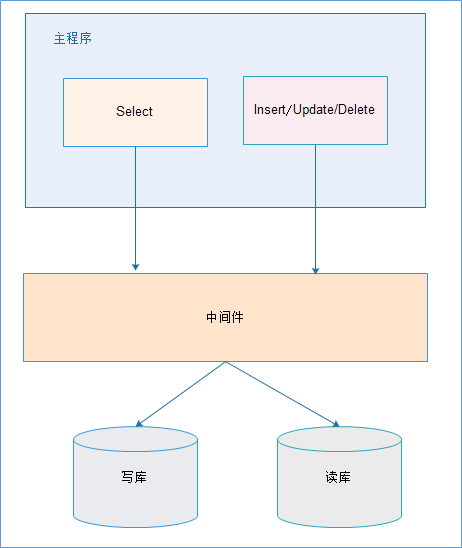
优点:
- 源程序不需要做任何改动就可以实现读写分离;
- 动态添加数据源不需要重启程序;
缺点:
程序依赖于中间件,会导致切换数据库变得困难;
由中间件做了中转代理,性能有所下降;
# Spring方案
# 原理
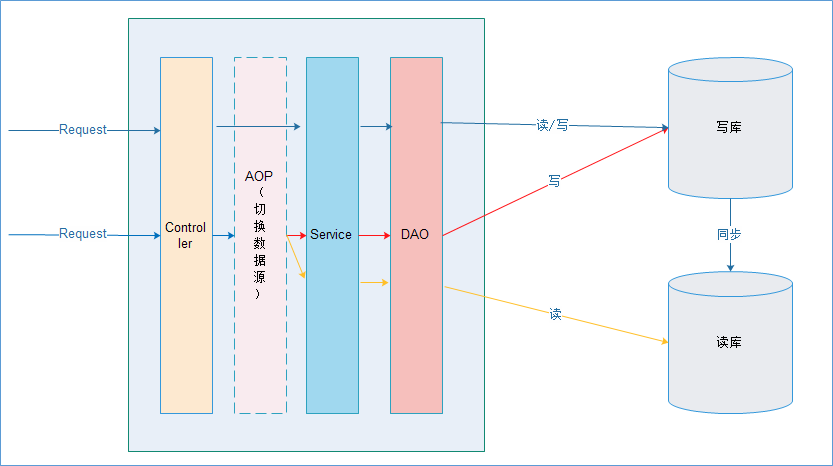
在进入Service之前,使用AOP来做出判断,是使用写库还是读库,判断依据可以根据方法名判断,比如说以query、find、get等开头的就走读库,其他的走写库。
# DynamicDataSource
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* 定义动态数据源,实现通过集成Spring提供的AbstractRoutingDataSource,只需要实现determineCurrentLookupKey方法即可
* 由于DynamicDataSource是单例的,线程不安全的,所以采用ThreadLocal保证线程安全,由DynamicDataSourceHolder完成。
* @author binghe
*/
public class DynamicDataSource extends AbstractRoutingDataSource{
@Override
protected Object determineCurrentLookupKey() {
// 使用DynamicDataSourceHolder保证线程安全,并且得到当前线程中的数据源key
return DynamicDataSourceHolder.getDataSourceKey();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# DynamicDataSourceHolder
/**
* 使用ThreadLocal技术来记录当前线程中的数据源的key
* @author binghe
*/
public class DynamicDataSourceHolder {
//写库对应的数据源key
private static final String MASTER = "master";
//读库对应的数据源key
private static final String SLAVE = "slave";
//使用ThreadLocal记录当前线程的数据源key
private static final ThreadLocal<String> holder = new ThreadLocal<String>();
/**
* 设置数据源key
* @param key
*/
public static void putDataSourceKey(String key) {
holder.set(key);
}
/**
* 获取数据源key
* @return
*/
public static String getDataSourceKey() {
return holder.get();
}
/**
* 标记写库
*/
public static void markMaster(){
putDataSourceKey(MASTER);
}
/**
* 标记读库
*/
public static void markSlave(){
putDataSourceKey(SLAVE);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# DataSourceAspect
import org.apache.commons.lang3.StringUtils;
import org.aspectj.lang.JoinPoint;
/**
* 定义数据源的AOP切面,通过该Service的方法名判断是应该走读库还是写库
* @author binghe
*/
public class DataSourceAspect {
/**
* 在进入Service方法之前执行
* @param point 切面对象
*/
public void before(JoinPoint point) {
// 获取到当前执行的方法名
String methodName = point.getSignature().getName();
if (isSlave(methodName)) {
// 标记为读库
DynamicDataSourceHolder.markSlave();
} else {
// 标记为写库
DynamicDataSourceHolder.markMaster();
}
}
/**
* 判断是否为读库
*
* @param methodName
* @return
*/
private Boolean isSlave(String methodName) {
// 方法名以query、find、get开头的方法名走从库
return StringUtils.startsWithAny(methodName, "query", "find", "get");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 配置2个数据源
jdbc.properties
jdbc.master.driver=com.mysql.jdbc.Driver
jdbc.master.url=jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
jdbc.master.username=root
jdbc.master.password=123456
jdbc.slave01.driver=com.mysql.jdbc.Driver
jdbc.slave01.url=jdbc:mysql://127.0.0.1:3307/test?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
jdbc.slave01.username=root
jdbc.slave01.password=123456
2
3
4
5
6
7
8
9
10
# 定义连接池
<!-- 配置连接池 -->
<bean id="masterDataSource" class="com.jolbox.bonecp.BoneCPDataSource"
destroy-method="close">
<!-- 数据库驱动 -->
<property name="driverClass" value="${jdbc.master.driver}" />
<!-- 相应驱动的jdbcUrl -->
<property name="jdbcUrl" value="${jdbc.master.url}" />
<!-- 数据库的用户名 -->
<property name="username" value="${jdbc.master.username}" />
<!-- 数据库的密码 -->
<property name="password" value="${jdbc.master.password}" />
<!-- 检查数据库连接池中空闲连接的间隔时间,单位是分,默认值:240,如果要取消则设置为0 -->
<property name="idleConnectionTestPeriod" value="60" />
<!-- 连接池中未使用的链接最大存活时间,单位是分,默认值:60,如果要永远存活设置为0 -->
<property name="idleMaxAge" value="30" />
<!-- 每个分区最大的连接数 -->
<property name="maxConnectionsPerPartition" value="150" />
<!-- 每个分区最小的连接数 -->
<property name="minConnectionsPerPartition" value="5" />
</bean>
<!-- 配置连接池 -->
<bean id="slave01DataSource" class="com.jolbox.bonecp.BoneCPDataSource"
destroy-method="close">
<!-- 数据库驱动 -->
<property name="driverClass" value="${jdbc.slave01.driver}" />
<!-- 相应驱动的jdbcUrl -->
<property name="jdbcUrl" value="${jdbc.slave01.url}" />
<!-- 数据库的用户名 -->
<property name="username" value="${jdbc.slave01.username}" />
<!-- 数据库的密码 -->
<property name="password" value="${jdbc.slave01.password}" />
<!-- 检查数据库连接池中空闲连接的间隔时间,单位是分,默认值:240,如果要取消则设置为0 -->
<property name="idleConnectionTestPeriod" value="60" />
<!-- 连接池中未使用的链接最大存活时间,单位是分,默认值:60,如果要永远存活设置为0 -->
<property name="idleMaxAge" value="30" />
<!-- 每个分区最大的连接数 -->
<property name="maxConnectionsPerPartition" value="150" />
<!-- 每个分区最小的连接数 -->
<property name="minConnectionsPerPartition" value="5" />
</bean>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 定义DataSource
<!-- 定义数据源,使用自己实现的数据源 -->
<bean id="dataSource" class="cn.itcast.usermanage.spring.DynamicDataSource">
<!-- 设置多个数据源 -->
<property name="targetDataSources">
<map key-type="java.lang.String">
<!-- 这个key需要和程序中的key一致 -->
<entry key="master" value-ref="masterDataSource"/>
<entry key="slave" value-ref="slave01DataSource"/>
</map>
</property>
<!-- 设置默认的数据源,这里默认走写库 -->
<property name="defaultTargetDataSource" ref="masterDataSource"/>
</bean>
2
3
4
5
6
7
8
9
10
11
12
13
# 配置事务管理以及动态切换数据源切面
# 定义事务管理器
<!-- 定义事务管理器 -->
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
2
3
4
5
# 定义事务策略
<!-- 定义事务策略 -->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<!--定义查询方法都是只读的 -->
<tx:method name="query*" read-only="true" />
<tx:method name="find*" read-only="true" />
<tx:method name="get*" read-only="true" />
<!-- 主库执行操作,事务传播行为定义为默认行为 -->
<tx:method name="save*" propagation="REQUIRED" />
<tx:method name="update*" propagation="REQUIRED" />
<tx:method name="delete*" propagation="REQUIRED" />
<!--其他方法使用默认事务策略 -->
<tx:method name="*" />
</tx:attributes>
</tx:advice>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 定义切面
<!-- 定义AOP切面处理器 -->
<bean class="cn.itcast.usermanage.spring.DataSourceAspect" id="dataSourceAspect" />
<aop:config>
<!-- 定义切面,所有的service的所有方法 -->
<aop:pointcut id="txPointcut" expression="execution(* xx.xxx.xxxxxxx.service.*.*(..))" />
<!-- 应用事务策略到Service切面 -->
<aop:advisor advice-ref="txAdvice" pointcut-ref="txPointcut"/>
<!-- 将切面应用到自定义的切面处理器上,-9999保证该切面优先级最高执行 -->
<aop:aspect ref="dataSourceAspect" order="-9999">
<aop:before method="before" pointcut-ref="txPointcut" />
</aop:aspect>
</aop:config>
2
3
4
5
6
7
8
9
10
11
12
13
14
# 改进切面实现,使用事务策略规则匹配
之前的实现我们是将通过方法名匹配,而不是使用事务策略中的定义,我们使用事务管理策略中的规则匹配。
# 改进后的配置
<!-- 定义AOP切面处理器 -->
<bean class="cn.itcast.usermanage.spring.DataSourceAspect" id="dataSourceAspect">
<!-- 指定事务策略 -->
<property name="txAdvice" ref="txAdvice"/>
<!-- 指定slave方法的前缀(非必须) -->
<property name="slaveMethodStart" value="query,find,get"/>
</bean>
2
3
4
5
6
7
# 改进后的实现
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import org.apache.commons.lang3.StringUtils;
import org.aspectj.lang.JoinPoint;
import org.springframework.transaction.interceptor.NameMatchTransactionAttributeSource;
import org.springframework.transaction.interceptor.TransactionAttribute;
import org.springframework.transaction.interceptor.TransactionAttributeSource;
import org.springframework.transaction.interceptor.TransactionInterceptor;
import org.springframework.util.PatternMatchUtils;
import org.springframework.util.ReflectionUtils;
/**
* 定义数据源的AOP切面,该类控制了使用Master还是Slave。
* 如果事务管理中配置了事务策略,则采用配置的事务策略中的标记了ReadOnly的方法是用Slave,其它使用Master。
* 如果没有配置事务管理的策略,则采用方法名匹配的原则,以query、find、get开头方法用Slave,其它用Master。
* @author binghe
*
*/
public class DataSourceAspect {
private List<String> slaveMethodPattern = new ArrayList<String>();
private static final String[] defaultSlaveMethodStart = new String[]{ "query", "find", "get" };
private String[] slaveMethodStart;
/**
* 读取事务管理中的策略
* @param txAdvice
* @throws Exception
*/
@SuppressWarnings("unchecked")
public void setTxAdvice(TransactionInterceptor txAdvice) throws Exception {
if (txAdvice == null) {
// 没有配置事务管理策略
return;
}
//从txAdvice获取到策略配置信息
TransactionAttributeSource transactionAttributeSource = txAdvice.getTransactionAttributeSource();
if (!(transactionAttributeSource instanceof NameMatchTransactionAttributeSource)) {
return;
}
//使用反射技术获取到NameMatchTransactionAttributeSource对象中的nameMap属性值
NameMatchTransactionAttributeSource matchTransactionAttributeSource = (NameMatchTransactionAttributeSource) transactionAttributeSource;
Field nameMapField = ReflectionUtils.findField(NameMatchTransactionAttributeSource.class, "nameMap");
nameMapField.setAccessible(true); //设置该字段可访问
//获取nameMap的值
Map<String, TransactionAttribute> map = (Map<String, TransactionAttribute>) nameMapField.get(matchTransactionAttributeSource);
//遍历nameMap
for (Map.Entry<String, TransactionAttribute> entry : map.entrySet()) {
if (!entry.getValue().isReadOnly()) {//判断之后定义了ReadOnly的策略才加入到slaveMethodPattern
continue;
}
slaveMethodPattern.add(entry.getKey());
}
}
/**
* 在进入Service方法之前执行
*
* @param point 切面对象
*/
public void before(JoinPoint point) {
// 获取到当前执行的方法名
String methodName = point.getSignature().getName();
boolean isSlave = false;
if (slaveMethodPattern.isEmpty()) {
// 当前Spring容器中没有配置事务策略,采用方法名匹配方式
isSlave = isSlave(methodName);
} else {
// 使用策略规则匹配
for (String mappedName : slaveMethodPattern) {
if (isMatch(methodName, mappedName)) {
isSlave = true;
break;
}
}
}
if (isSlave) {
// 标记为读库
DynamicDataSourceHolder.markSlave();
} else {
// 标记为写库
DynamicDataSourceHolder.markMaster();
}
}
/**
* 判断是否为读库
*
* @param methodName
* @return
*/
private Boolean isSlave(String methodName) {
// 方法名以query、find、get开头的方法名走从库
return StringUtils.startsWithAny(methodName, getSlaveMethodStart());
}
/**
* 通配符匹配
*
* Return if the given method name matches the mapped name.
* <p>
* The default implementation checks for "xxx*", "*xxx" and "*xxx*" matches, as well as direct
* equality. Can be overridden in subclasses.
*
* @param methodName the method name of the class
* @param mappedName the name in the descriptor
* @return if the names match
* @see org.springframework.util.PatternMatchUtils#simpleMatch(String, String)
*/
protected boolean isMatch(String methodName, String mappedName) {
return PatternMatchUtils.simpleMatch(mappedName, methodName);
}
/**
* 用户指定slave的方法名前缀
* @param slaveMethodStart
*/
public void setSlaveMethodStart(String[] slaveMethodStart) {
this.slaveMethodStart = slaveMethodStart;
}
public String[] getSlaveMethodStart() {
if(this.slaveMethodStart == null){
// 没有指定,使用默认
return defaultSlaveMethodStart;
}
return slaveMethodStart;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
# 一主多从的实现
很多实际使用场景下都是采用“一主多从”的架构的,所有我们现在对这种架构做支持,目前只需要修改DynamicDataSource即可。
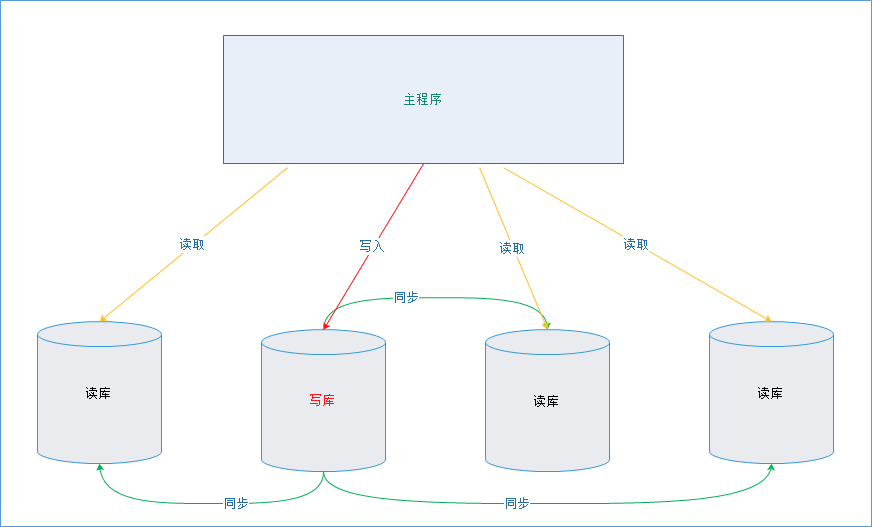
# 实现
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
import javax.sql.DataSource;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import org.springframework.util.ReflectionUtils;
/**
* 定义动态数据源,实现通过集成Spring提供的AbstractRoutingDataSource,只需要实现determineCurrentLookupKey方法即可
* 由于DynamicDataSource是单例的,线程不安全的,所以采用ThreadLocal保证线程安全,由DynamicDataSourceHolder完成。
* @author binghe
*
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
private static final Logger LOGGER = LoggerFactory.getLogger(DynamicDataSource.class);
private Integer slaveCount;
// 轮询计数,初始为-1,AtomicInteger是线程安全的
private AtomicInteger counter = new AtomicInteger(-1);
// 记录读库的key
private List<Object> slaveDataSources = new ArrayList<Object>(0);
@Override
protected Object determineCurrentLookupKey() {
// 使用DynamicDataSourceHolder保证线程安全,并且得到当前线程中的数据源key
if (DynamicDataSourceHolder.isMaster()) {
Object key = DynamicDataSourceHolder.getDataSourceKey();
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("当前DataSource的key为: " + key);
}
return key;
}
Object key = getSlaveKey();
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("当前DataSource的key为: " + key);
}
return key;
}
@SuppressWarnings("unchecked")
@Override
public void afterPropertiesSet() {
super.afterPropertiesSet();
// 由于父类的resolvedDataSources属性是私有的子类获取不到,需要使用反射获取
Field field = ReflectionUtils.findField(AbstractRoutingDataSource.class, "resolvedDataSources");
field.setAccessible(true); // 设置可访问
try {
Map<Object, DataSource> resolvedDataSources = (Map<Object, DataSource>) field.get(this);
// 读库的数据量等于数据源总数减去写库的数量
this.slaveCount = resolvedDataSources.size() - 1;
for (Map.Entry<Object, DataSource> entry : resolvedDataSources.entrySet()) {
if (DynamicDataSourceHolder.MASTER.equals(entry.getKey())) {
continue;
}
slaveDataSources.add(entry.getKey());
}
} catch (Exception e) {
LOGGER.error("afterPropertiesSet error! ", e);
}
}
/**
* 轮询算法实现
*
* @return
*/
public Object getSlaveKey() {
// 得到的下标为:0、1、2、3……
Integer index = counter.incrementAndGet() % slaveCount;
if (counter.get() > 9999) { // 以免超出Integer范围
counter.set(-1); // 还原
}
return slaveDataSources.get(index);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
# MySQL主从复制
# 原理
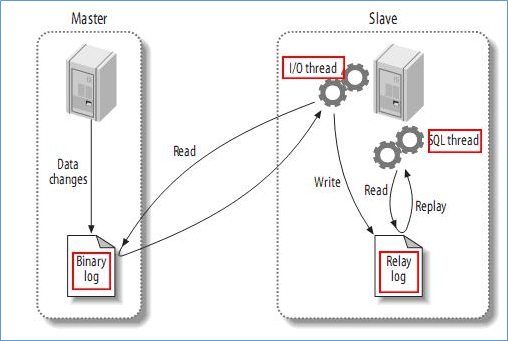
MySQL主(master)从(slave)复制的原理:
- master将数据改变记录到二进制日志(binarylog)中,也即是配置文件log-bin指定的文件(这些记录叫做二进制日志事件,binary log events)
- slave将master的binary logevents拷贝到它的中继日志(relay log)
- slave重做中继日志中的事件,将改变反映它自己的数据(数据重演)
# 主从配置需要注意的地方
- 主DB server和从DB server数据库的版本一致
- 主DB server和从DB server数据库数据一致[ 这里就会可以把主的备份在从上还原,也可以直接将主的数据目录拷贝到从的相应数据目录]
- 主DB server开启二进制日志,主DB server和从DB server的server_id都必须唯一
# 主库配置(windows,Linux下也类似)
在my.ini修改:
#开启主从复制,主库的配置
log-bin = mysql3306-bin
#指定主库serverid
server-id=101
#指定同步的数据库,如果不指定则同步全部数据库
binlog-do-db=mybatis_1128
2
3
4
5
6
执行SQL语句查询状态:
SHOW MASTER STATUS

需要记录下Position值,需要在从库中设置同步起始值。
# 在主库创建同步用户
#授权用户slave01使用123456密码登录mysql
grant replication slave on *.* to 'slave01'@'127.0.0.1' identified by '123456';
flush privileges;
2
3
# 从库配置
在my.ini修改
#指定serverid,只要不重复即可,从库也只有这一个配置,其他都在SQL语句中操作
server-id=102
2
接下来,从从库命令行执行如下SQL语句。
CHANGE MASTER TO
master_host='127.0.0.1',
master_user='slave01',
master_password='123456',
master_port=3306,
master_log_file='mysql3306-bin.000006',
master_log_pos=1120;
#启动slave同步
START SLAVE;
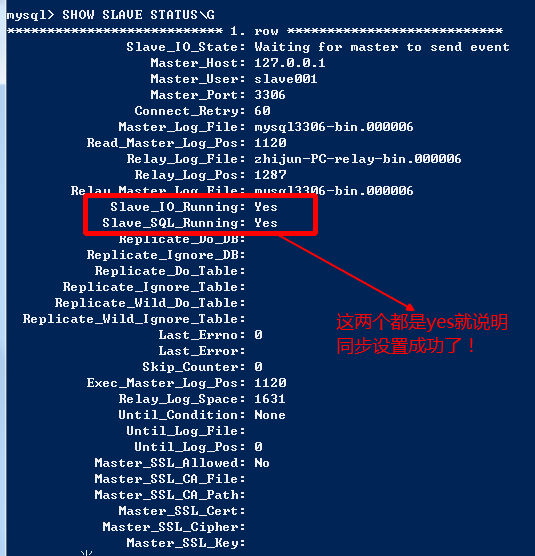
#查看同步状态
SHOW SLAVE STATUS;
2
3
4
5
6
7
8
9
10
11
12
13
# 冰河原创PDF
关注 冰河技术 微信公众号:
回复 “并发编程” 领取《深入理解高并发编程(第1版)》PDF文档。
回复 “并发源码” 领取《并发编程核心知识(源码分析篇 第1版)》PDF文档。
回复 ”限流“ 领取《亿级流量下的分布式解决方案》PDF文档。
回复 “设计模式” 领取《深入浅出Java23种设计模式》PDF文档。
回复 “Java8新特性” 领取 《Java8新特性教程》PDF文档。
回复 “分布式存储” 领取《跟冰河学习分布式存储技术》 PDF文档。
回复 “Nginx” 领取《跟冰河学习Nginx技术》PDF文档。
回复 “互联网工程” 领取《跟冰河学习互联网工程技术》PDF文档。
# 重磅福利
微信搜一搜【冰河技术】微信公众号,关注这个有深度的程序员,每天阅读超硬核技术干货,公众号内回复【PDF】有我准备的一线大厂面试资料和我原创的超硬核PDF技术文档,以及我为大家精心准备的多套简历模板(不断更新中),希望大家都能找到心仪的工作,学习是一条时而郁郁寡欢,时而开怀大笑的路,加油。如果你通过努力成功进入到了心仪的公司,一定不要懈怠放松,职场成长和新技术学习一样,不进则退。如果有幸我们江湖再见!
另外,我开源的各个PDF,后续我都会持续更新和维护,感谢大家长期以来对冰河的支持!!
# 星球服务
加入星球,你将获得:
1.项目学习:微服务入门必备的SpringCloud Alibaba实战项目、手写RPC项目—所有大厂都需要的项目【含上百个经典面试题】、深度解析Spring6核心技术—只要学习Java就必须深度掌握的框架【含数十个经典思考题】、Seckill秒杀系统项目—进大厂必备高并发、高性能和高可用技能。
2.框架源码:手写RPC项目—所有大厂都需要的项目【含上百个经典面试题】、深度解析Spring6核心技术—只要学习Java就必须深度掌握的框架【含数十个经典思考题】。
3.硬核技术:深入理解高并发系列(全册)、深入理解JVM系列(全册)、深入浅出Java设计模式(全册)、MySQL核心知识(全册)。
4.技术小册:深入理解高并发编程(第1版)、深入理解高并发编程(第2版)、从零开始手写RPC框架、SpringCloud Alibaba实战、冰河的渗透实战笔记、MySQL核心知识手册、Spring IOC核心技术、Nginx核心技术、面经手册等。
5.技术与就业指导:提供相关就业辅导和未来发展指引,冰河从初级程序员不断沉淀,成长,突破,一路成长为互联网资深技术专家,相信我的经历和经验对你有所帮助。
冰河的知识星球是一个简单、干净、纯粹交流技术的星球,不吹水,目前加入享5折优惠,价值远超门票。加入星球的用户,记得添加冰河微信:hacker_binghe,冰河拉你进星球专属VIP交流群。
# 星球重磅福利
跟冰河一起从根本上提升自己的技术能力,架构思维和设计思路,以及突破自身职场瓶颈,冰河特推出重大优惠活动,扫码领券进行星球,直接立减149元,相当于5折, 这已经是星球最大优惠力度!
领券加入星球,跟冰河一起学习《SpringCloud Alibaba实战》、《手撸RPC专栏》和《Spring6核心技术》,更有已经上新的《大规模分布式Seckill秒杀系统》,从零开始介绍原理、设计架构、手撸代码。后续更有硬核中间件项目和业务项目,而这些都是你升职加薪必备的基础技能。
100多元就能学这么多硬核技术、中间件项目和大厂秒杀系统,如果是我,我会买他个终身会员!
# 其他方式加入星球
- 链接 :打开链接 http://m6z.cn/6aeFbs (opens new window) 加入星球。
- 回复 :在公众号 冰河技术 回复 星球 领取优惠券加入星球。
特别提醒: 苹果用户进圈或续费,请加微信 hacker_binghe 扫二维码,或者去公众号 冰河技术 回复 星球 扫二维码加入星球。
# 星球规划
后续冰河还会在星球更新大规模中间件项目和深度剖析核心技术的专栏,目前已经规划的专栏如下所示。
# 中间件项目
- 《大规模分布式定时调度中间件项目实战(非Demo)》:全程手撸代码。
- 《大规模分布式IM(即时通讯)项目实战(非Demo)》:全程手撸代码。
- 《大规模分布式网关项目实战(非Demo)》:全程手撸代码。
- 《手写Redis》:全程手撸代码。
- 《手写JVM》全程手撸代码。
# 超硬核项目
- 《从零落地秒杀系统项目》:全程手撸代码,在阿里云实现压测(已上新)。
- 《大规模电商系统商品详情页项目》:全程手撸代码,在阿里云实现压测。
- 其他待规划的实战项目,小伙伴们也可以提一些自己想学的,想一起手撸的实战项目。。。
既然星球规划了这么多内容,那么肯定就会有小伙伴们提出疑问:这么多内容,能更新完吗?我的回答就是:一个个攻破呗,咱这星球干就干真实中间件项目,剖析硬核技术和项目,不做Demo。初衷就是能够让小伙伴们学到真正的核心技术,不再只是简单的做CRUD开发。所以,每个专栏都会是硬核内容,像《SpringCloud Alibaba实战》、《手撸RPC专栏》和《Spring6核心技术》就是很好的示例。后续的专栏只会比这些更加硬核,杜绝Demo开发。
小伙伴们跟着冰河认真学习,多动手,多思考,多分析,多总结,有问题及时在星球提问,相信在技术层面,都会有所提高。将学到的知识和技术及时运用到实际的工作当中,学以致用。星球中不少小伙伴都成为了公司的核心技术骨干,实现了升职加薪的目标。
# 联系冰河
# 加群交流
本群的宗旨是给大家提供一个良好的技术学习交流平台,所以杜绝一切广告!由于微信群人满 100 之后无法加入,请扫描下方二维码先添加作者 “冰河” 微信(hacker_binghe),备注:星球编号。

# 公众号
分享各种编程语言、开发技术、分布式与微服务架构、分布式数据库、分布式事务、云原生、大数据与云计算技术和渗透技术。另外,还会分享各种面试题和面试技巧。内容在 冰河技术 微信公众号首发,强烈建议大家关注。

# 视频号
定期分享各种编程语言、开发技术、分布式与微服务架构、分布式数据库、分布式事务、云原生、大数据与云计算技术和渗透技术。另外,还会分享各种面试题和面试技巧。

# 星球
加入星球 冰河技术 (opens new window),可以获得本站点所有学习内容的指导与帮助。如果你遇到不能独立解决的问题,也可以添加冰河的微信:hacker_binghe, 我们一起沟通交流。另外,在星球中不只能学到实用的硬核技术,还能学习实战项目!
关注 冰河技术 (opens new window)公众号,回复 星球 可以获取入场优惠券。

